Case Study: Building a Financial Document Processing Pipeline with Transaction Safety
Table of contents
This post applies the 9-step case study structure from the GenAI System Design Framework.
Problem Statement
A mid-to-large enterprise processes tens of thousands of invoices, purchase orders, and payment documents every month. The documents arrive in mixed formats: PDFs from vendors, email attachments, scanned images, and occasionally structured EDI feeds. Each document needs to be extracted, matched against existing purchase orders, validated for compliance, and routed to the correct payment workflow.
Today this is mostly manual. An accounts payable team opens each document, keys in line items, cross-references PO numbers in the ERP, flags mismatches, and submits for approval. Straight-through processing rates (documents that flow from ingestion to payment without human touch) hover around 30-40% at most organizations. The rest require manual intervention for extraction errors, PO mismatches, duplicate detection, or compliance exceptions.
What we’re building: a multi-agent pipeline that ingests financial documents, extracts structured data, reconciles against purchase orders, runs compliance validation, and initiates payment, with transaction safety guarantees across the full chain.
Primary users: accounts payable teams who currently process documents manually.
Secondary users: finance controllers who approve exceptions, compliance officers who audit the pipeline, and platform teams who operate it.
What This System Is Not
This is not an accounts payable chatbot. There’s no conversational interface. Documents flow in, structured payment instructions flow out. The agents don’t interact with users in real time (except through asynchronous review queues). This is a pipeline, not a dialogue system.
It’s also not a simple OCR-to-database pipeline. If the problem were just text extraction, you’d use a traditional OCR service and call it done. The hard part is the reconciliation logic (matching extracted line items against PO terms that may have been amended three times), the compliance validation (which varies by jurisdiction, vendor tier, and document type), and the fact that the pipeline writes to a ledger. A wrong write is not a bad recommendation. It’s a financial discrepancy that triggers an audit.
Step 0: Why GenAI?
The extraction step is where GenAI earns its keep. Traditional OCR plus template-based extraction works well when documents follow a known layout. A specific vendor always sends invoices in the same PDF format, and you build a template that maps coordinates to fields. This breaks when you have 500 vendors, each with their own invoice format, and 15% of documents are scanned images with varying quality.
An LLM with vision capabilities (GPT-4o, Claude Sonnet, Gemini) can extract structured fields from documents it has never seen before. No template. No layout training. You hand it an invoice image and a JSON schema, and it returns the line items, amounts, tax calculations, and PO references. Extraction accuracy on well-formatted PDFs is typically 92-96% without any document-specific training.
But here’s where teams get into trouble: they see the extraction working and assume the whole pipeline should be LLM-powered. Reconciliation against purchase orders is mostly a database join with fuzzy matching on a few fields. Running that through an LLM is slower, more expensive, and less reliable than a deterministic matcher with an LLM fallback for ambiguous cases. Payment initiation is a structured API call. There is zero reason to have an LLM generate payment instructions from scratch when you can compose them deterministically from validated data.
The cost math reinforces this. LLM extraction costs roughly $0.02-0.05 per document (depending on page count and model). A deterministic PO matcher costs effectively nothing. If you route everything through a frontier model, you’re paying $0.10-0.20 per document for steps that don’t need generative capabilities. At 50,000 documents per month, that’s the difference between $2,500 and $10,000 in inference costs, and the cheaper version is actually more reliable for the non-extraction steps.
GenAI handles: document extraction (unstructured to structured), ambiguous PO matching (when fuzzy matching returns multiple candidates), and compliance edge cases (interpreting regulatory text against document specifics). Everything else stays deterministic.
Step 1: Requirements
Functional Requirements
- Ingest documents from multiple channels: email attachments, SFTP drops, API uploads, scanned images
- Extract structured fields (vendor, invoice number, line items, amounts, tax, PO references, payment terms) from arbitrary document formats
- Match extracted data against purchase orders in the ERP, handling partial matches, amended POs, and multi-line PO splits
- Validate against compliance rules: duplicate invoice detection, three-way match (PO, goods receipt, invoice), jurisdictional tax rules, vendor-specific terms
- Route for human review when extraction confidence is low or compliance validation fails
- Initiate payment through downstream payment systems (ERP, treasury, banking APIs)
- Maintain full audit trail: every extraction, match decision, validation result, and payment instruction must be traceable
Non-Functional Requirements
- Consistency: Every payment instruction must be idempotent. Processing the same document twice must not create duplicate payments. This is the single most important non-functional requirement.
- Latency: Not real-time. Batch processing with a target of under 5 minutes per document end-to-end for straight-through cases. Human review cases can take hours or days.
- Availability: 99.5% uptime during business hours. Documents queue during downtime, nothing is lost.
- Compliance: Full audit log. Every agent decision must be traceable to the input document and the intermediate results that led to it. SOX compliance for publicly traded companies means you cannot have opaque AI decisions in the payment chain.
Scale Assumptions
A mid-size enterprise processes 30,000-80,000 documents per month. Peak periods (month-end close, quarter-end) can see 3-5x the daily average. At 50,000 documents per month with an average of 2 pages each, that’s roughly 100,000 page extractions. This is not a high-QPS inference problem. Peak throughput is maybe 200-300 documents per hour during month-end close. The challenge is not throughput but correctness and transaction safety across a multi-step pipeline.
Quality Metrics
| Metric | Target | Why this number |
|---|---|---|
| Extraction accuracy (field-level) | >95% | Below this, human review volume exceeds manual processing cost |
| Straight-through processing rate | >70% | Industry benchmark for automated AP. Below 70% and ROI is marginal |
| Duplicate payment rate | 0% | Any duplicate payment is a financial control failure |
| PO match accuracy | >92% | False positives (wrong PO) are worse than false negatives (escalation) |
| Compliance validation precision | >98% | False flags are acceptable (human reviews them). Misses are not |
Trade-offs to Acknowledge
There are a few tensions in the requirements that shape the architecture:
| Trade-off | Option A | Option B | Our lean |
|---|---|---|---|
| Extraction accuracy vs throughput | 95% auto-extraction, process everything fast | 99.5% with 20% routed to human review | Option B. Financial documents cannot tolerate 5% error rate on amounts |
| Saga orchestration vs two-phase commit | Eventual consistency, compensating transactions | Strong consistency, higher latency, less flexible | Saga. Human review loops make synchronous 2PC impractical |
| Shared context store vs message passing | Single database all agents read/write, contention risk | Structured messages between agents, more isolation | Hybrid. Shared store for document state, message passing for agent coordination |
| Sync pipeline vs async event-driven | Simpler to reason about, harder to pause/resume | More complex, but human-in-the-loop is natural | Async. Human review gates can pause for days. Sync pipelines can’t handle that |
Step 2: Architecture
Why Multiple Agents?
A single model processing the full pipeline (extract, match, validate, pay) fails for the same reasons a monolithic microservice fails. The extraction task needs vision capabilities and unstructured reasoning. Reconciliation needs precise database lookups and fuzzy matching. Compliance validation needs rule evaluation against jurisdiction-specific regulations. Payment initiation needs strict schema adherence and idempotency. These are genuinely different capabilities with different model requirements, different failure modes, and different rollback semantics.
| Concern | Single Pipeline | Multi-Agent with Saga |
|---|---|---|
| Model selection | One model does everything (expensive, overkill for matching) | Right model per task (vision for extraction, small model for matching, rules engine for compliance) |
| Failure isolation | Extraction failure blocks payment. No partial progress | Each agent can fail independently. Partial results preserved |
| Rollback | All or nothing. If payment fails, re-extract everything | Compensating transaction per step. Roll back only what’s needed |
| Human review | Blocks the entire pipeline | Only the specific step pauses. Other documents continue |
| Audit trail | One opaque decision | Each step logged separately with inputs and outputs |
The Agents
Four agents, each with a narrow scope:
Extraction Agent: Takes raw documents (PDF, image, email) and produces structured JSON. Uses a vision-capable LLM (GPT-4o or Claude Sonnet) with a strict output schema. This is the only agent that needs a frontier model. Outputs: vendor name, invoice number, line items (description, quantity, unit price, total), tax amounts, PO references, payment terms, due date.
Reconciliation Agent: Takes the Extraction Agent’s output and matches it against purchase orders in the ERP. Primarily deterministic: exact match on PO number, fuzzy match on line item descriptions, tolerance-based match on amounts (within 2% or $50, whichever is less). Falls back to an LLM for ambiguous cases where multiple POs are plausible candidates. Outputs: matched PO ID, match confidence, discrepancy details if any.
Compliance Agent: Takes the matched document-PO pair and validates against compliance rules. Three-way match (PO amount, goods receipt quantity, invoice amount). Duplicate invoice detection (same vendor, same amount, within 30 days). Jurisdictional tax validation. Vendor-specific terms (early payment discounts, net terms). Mostly rule-based with an LLM fallback for interpreting non-standard contract terms. Outputs: validation result (pass/fail/review), list of flags with severity.
Payment Agent: Takes a fully validated document and initiates payment. This agent does not use an LLM. It’s a deterministic service that composes payment instructions from validated data, applies idempotency keys, and submits to the payment system. The reason it’s still called an “agent” in this architecture is that it participates in the saga and has compensation logic (void a payment if a downstream step fails).
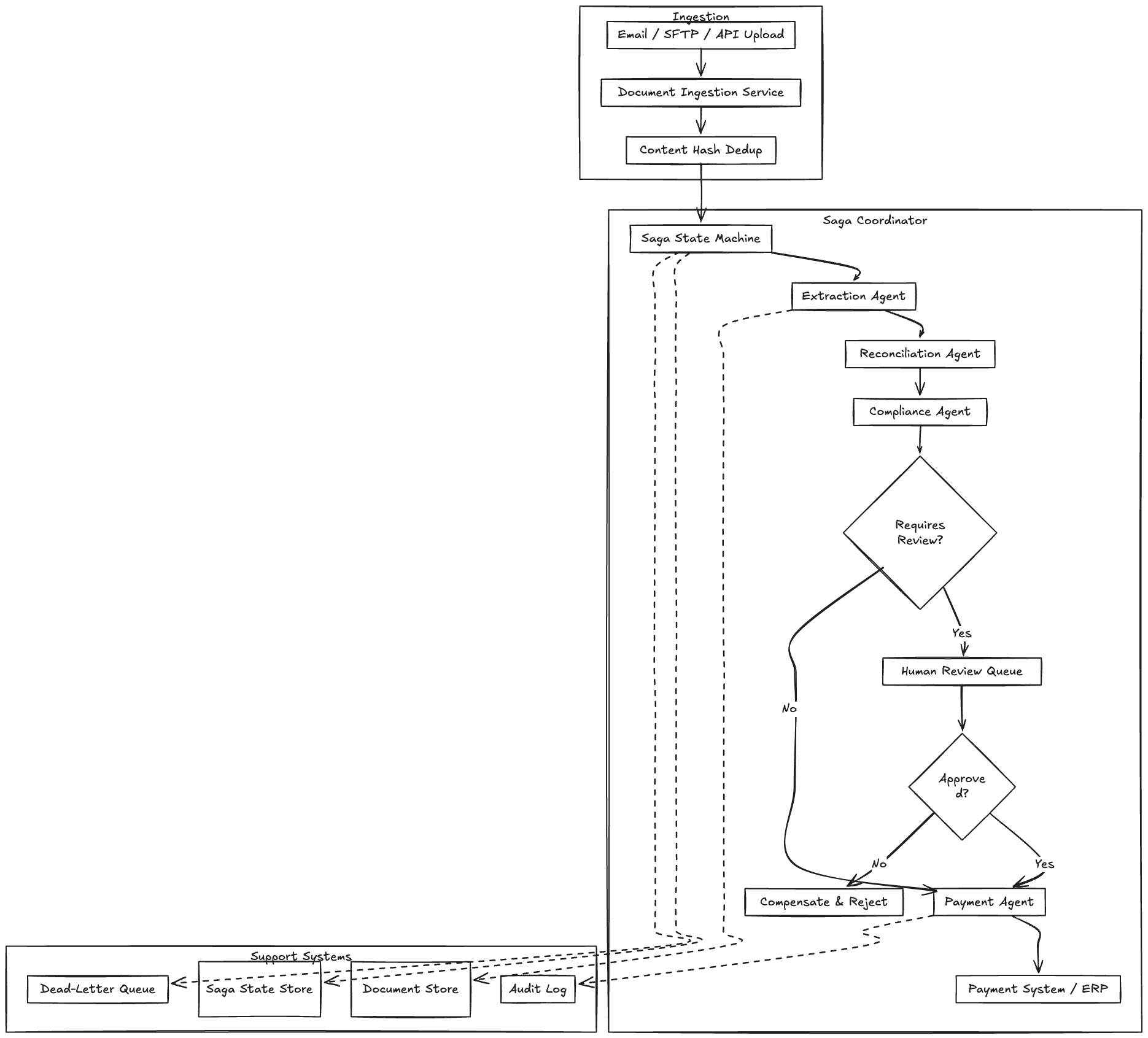
The Saga Coordinator
The saga coordinator is the central orchestrator. It does not process documents itself. It manages the state machine that each document flows through, triggers agent steps, handles retries, manages compensation on failure, and provides visibility into where every document is in the pipeline.
This is not an LLM. It’s a deterministic workflow engine. Think Temporal, AWS Step Functions, or a custom state machine backed by a durable queue. The choice matters and we’ll cover it in Step 4. The key design decision is that the coordinator owns the transaction boundary, not the individual agents. An agent doesn’t decide to retry or compensate. The coordinator does, based on the agent’s output and the current saga state.
Step 3: Saga Orchestration and Transaction Safety
This is where financial document processing diverges sharply from most agentic systems. In a chatbot, if a tool call fails, you apologize and try again. In a payment pipeline, if step 3 of 5 fails, you need to undo steps 1 and 2 in a specific order, and the undo operations themselves can fail.
Why Not Two-Phase Commit?
Two-phase commit (2PC) is the textbook answer for distributed transactions. All participants vote to commit, and if everyone agrees, the coordinator sends the commit signal. If anyone votes no, everyone rolls back.
| Two-Phase Commit | Saga Pattern | |
|---|---|---|
| Consistency model | Strong (all or nothing) | Eventual (compensating transactions) |
| Latency | High (all participants must respond before commit) | Lower per step (each step commits independently) |
| Human-in-the-loop | Impractical (lock held while human reviews for hours?) | Natural (checkpoint, resume after review) |
| Failure handling | Coordinator crash during commit = unclear state | Each step is committed. Compensation is explicit |
| Participant availability | All must be available simultaneously | Steps can execute hours apart |
| Complexity | Simpler mental model | More complex (compensation logic per step) |
The human review loop kills 2PC. When the Compliance Agent flags a document for review, the workflow pauses until a finance controller approves or rejects it. That can take hours or days. You cannot hold a distributed lock across three systems for two days while someone reviews an invoice. The saga pattern is the only practical choice for workflows that include human decision points.
Saga Flow
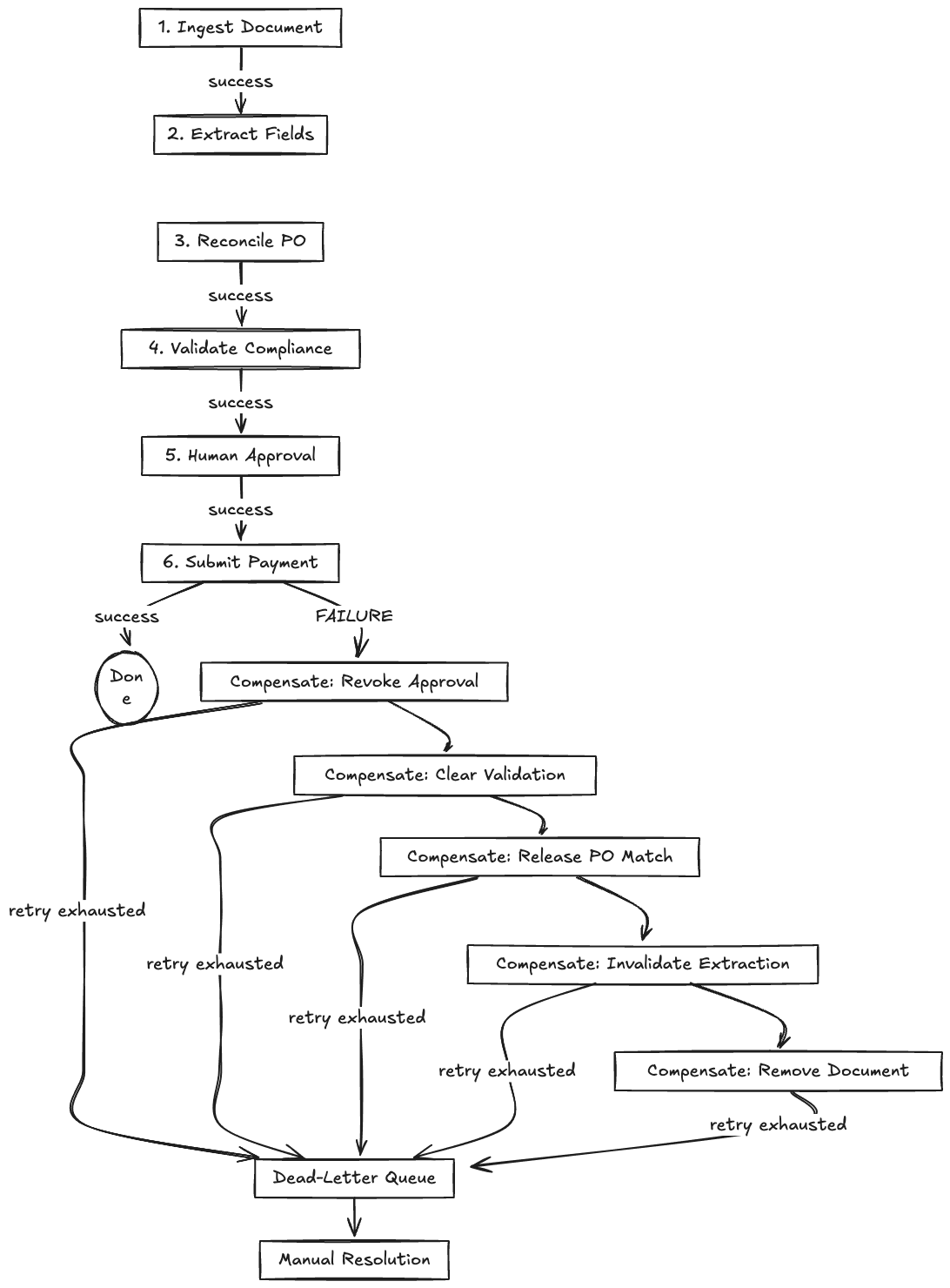
Each document flows through the saga as a sequence of steps. Every step has a forward action and a compensation action:
| Step | Forward Action | Compensation Action | Idempotency Key |
|---|---|---|---|
| 1. Ingest | Store raw document, assign document ID | Delete stored document | doc_hash + source_channel |
| 2. Extract | Run Extraction Agent, store structured result | Mark extraction as invalidated | doc_id + extraction_version |
| 3. Reconcile | Match against POs, create tentative match record | Release PO match reservation | doc_id + po_id + match_version |
| 4. Validate | Run compliance checks, store validation result | Clear validation flags | doc_id + validation_run_id |
| 5. Approve | Route to human review (if needed), record approval | Revoke approval record | doc_id + approval_id |
| 6. Pay | Submit payment instruction to payment system | Void/reverse the payment | doc_id + payment_instruction_id |
The idempotency key on each step is critical. If the Extraction Agent times out and the coordinator retries, the same extraction must not create a duplicate record. The key doc_id + extraction_version means the second attempt either returns the cached result (if the first attempt actually succeeded but the response was lost) or overwrites it (if it genuinely failed). Either way, no duplicate.
Compensation: The Hard Part
Forward actions are straightforward. Compensation is where things get messy. Consider this failure scenario:
- Document ingested (step 1, committed)
- Extraction succeeds (step 2, committed)
- PO match created (step 3, committed)
- Compliance validation passes (step 4, committed)
- Human approves (step 5, committed)
- Payment submission fails (step 6, the banking API is down)
Now you need to compensate steps 5 through 1 in reverse order. Step 5 compensation (revoke approval) is easy, it’s your own database. Step 3 compensation (release PO match reservation) is also internal. But what if during compensation, the ERP system that holds PO reservations is also down? You now have a partial saga with a failed compensation.
This is not a theoretical edge case. In production, the payment system and the ERP often share infrastructure or have correlated failure modes (same data center, same network partition). When the payment system is down, there’s a meaningful probability that the ERP is also degraded.
The solution is a compensation retry queue with exponential backoff and a dead-letter destination. Each compensation step is itself idempotent (using the same idempotency key pattern as the forward action). If compensation fails, it goes back on the queue. If it fails N times (typically 5-10 retries over 24 hours), it lands in a dead-letter queue for manual resolution. The dead-letter queue is not an afterthought. It’s a first-class operational surface with its own dashboard, alerting, and runbooks.
# Compensation retry with idempotency
class SagaCompensation:
def compensate_step(self, step: SagaStep, context: SagaContext):
idempotency_key = f"{context.doc_id}:{step.name}:{step.version}:compensate"
# Check if compensation already completed
if self.compensation_store.exists(idempotency_key):
return CompensationResult.ALREADY_COMPLETED
try:
result = step.compensate(context)
self.compensation_store.mark_completed(idempotency_key)
return result
except RetryableError as e:
self.retry_queue.enqueue(
step=step,
context=context,
backoff=exponential_backoff(attempt=context.retry_count),
max_retries=10
)
return CompensationResult.RETRYING
except NonRetryableError as e:
self.dead_letter_queue.enqueue(
step=step,
context=context,
error=e,
requires_manual_resolution=True
)
return CompensationResult.DEAD_LETTEREDIdempotency: Not Optional
Every agent operation in this pipeline needs an idempotency key. Not just the payment step. Every step. The reason is that the saga coordinator retries on timeout, and a timeout does not mean the operation failed. It means you don’t know. The operation might have succeeded and the response was lost. It might have failed. It might still be running.
Without idempotency keys, a retry after timeout can create:
- Duplicate extraction records (minor, wastes storage)
- Duplicate PO match reservations (moderate, blocks other invoices from matching the same PO)
- Duplicate payment instructions (critical, financial control failure)
The idempotency key pattern is the same everywhere: {document_id}:{step_name}:{version}. The version increments only when the input to that step materially changes (re-extraction after document amendment, not retry of the same extraction). Each agent checks the idempotency store before executing. If the key exists and the operation completed successfully, return the cached result. If the key exists and the operation failed, re-execute. If the key doesn’t exist, execute and store the result atomically.
For the Payment Agent specifically, the idempotency key is passed through to the banking API. Most payment APIs accept a client-generated idempotency key (Stripe’s Idempotency-Key header, for example). This means even if the Payment Agent itself retries, the banking system deduplicates at its end. Defense in depth.
Step 4: Long-Running Workflow Architecture
The Human Review Problem
In a pure machine pipeline, every step takes seconds. The saga runs start to finish in under a minute. But financial document processing has mandatory human review gates. A document flagged for compliance review doesn’t get processed in 5 minutes. It sits in a review queue until a finance controller looks at it. During month-end close, that queue might back up for 48 hours.
This means the workflow engine must support:
- Checkpoint: Save the full saga state (which steps completed, intermediate results, current step) durably
- Resume: Pick up exactly where it left off after hours or days
- Partial visibility: Show operators which documents are waiting on review, which are stuck, which are processing
- Timeout handling: If no human acts within 72 hours, auto-escalate or auto-reject
A simple queue-based pipeline can’t do this. If you’re processing a message off a queue and the consumer needs to wait 48 hours for human input, you’ve consumed the message and your consumer is blocked. You need durable execution.
Temporal-Style Durable Execution
Temporal (or its AWS equivalent, Step Functions; or the open-source alternative, Restate) provides exactly this pattern. The workflow is defined as code, but the engine checkpoints every state transition to a durable store. If the workflow process crashes, a new worker picks up from the last checkpoint.
The key abstraction is the workflow vs activity distinction:
# Temporal-style workflow definition (simplified)
class InvoiceProcessingWorkflow:
def run(self, document: RawDocument):
# Step 1: Ingest
doc_record = await workflow.execute_activity(
ingest_document,
document,
retry_policy=RetryPolicy(max_attempts=3),
start_to_close_timeout=timedelta(minutes=5)
)
# Step 2: Extract
extraction = await workflow.execute_activity(
run_extraction_agent,
doc_record,
retry_policy=RetryPolicy(max_attempts=2),
start_to_close_timeout=timedelta(minutes=10)
)
# Step 3: Reconcile
match_result = await workflow.execute_activity(
run_reconciliation_agent,
extraction,
retry_policy=RetryPolicy(max_attempts=3),
start_to_close_timeout=timedelta(minutes=5)
)
# Step 4: Validate
validation = await workflow.execute_activity(
run_compliance_agent,
match_result,
retry_policy=RetryPolicy(max_attempts=2),
start_to_close_timeout=timedelta(minutes=5)
)
# Step 5: Human review gate (if needed)
if validation.requires_review:
approval = await workflow.execute_activity(
request_human_review,
validation,
# Long timeout: human review can take days
start_to_close_timeout=timedelta(hours=72),
heartbeat_timeout=timedelta(hours=24)
)
if not approval.approved:
await self.compensate(doc_record, extraction, match_result)
return ProcessingResult.REJECTED
# Step 6: Pay
payment = await workflow.execute_activity(
submit_payment,
PaymentInstruction.from_validated(doc_record, match_result, validation),
retry_policy=RetryPolicy(max_attempts=5),
start_to_close_timeout=timedelta(minutes=15)
)
return ProcessingResult.COMPLETEDEvery execute_activity call is checkpointed. If the process crashes after extraction but before reconciliation, the workflow resumes from the reconciliation step when a new worker picks it up. The extraction is not re-run because its result was already persisted.
The heartbeat_timeout on the human review activity is important. The activity worker periodically heartbeats to Temporal to say “I’m still waiting for a human.” If the heartbeat stops (worker crashed, network partition), Temporal reassigns the activity to another worker. Without heartbeats, a crashed worker holding a human review task means that document disappears from the review queue until someone notices.
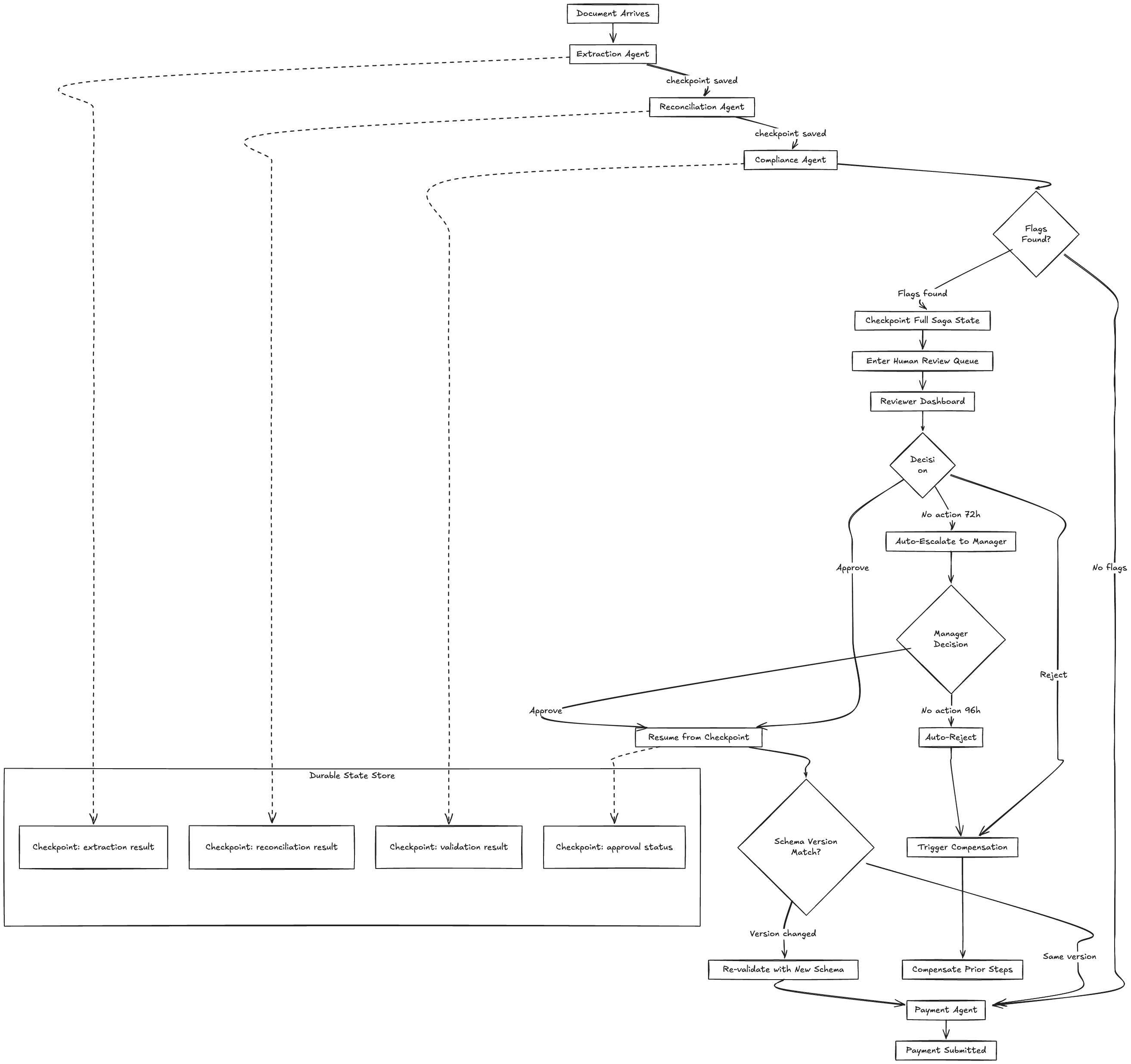
Checkpoint Schema Evolution
Here’s a failure mode that teams discover in production, not in design reviews. A document enters the pipeline on Monday. The Compliance Agent flags it for human review. The finance controller doesn’t get to it until Wednesday. In the meantime, the engineering team deploys a new version of the pipeline that changes the extraction schema (added a currency_code field to line items).
When the workflow resumes after human approval, the reconciliation result from Monday was produced by the old extraction schema. The Payment Agent expects the new schema with currency_code. The workflow either crashes or silently produces a payment instruction with missing data.
Solutions, roughly in order of preference:
| Approach | Complexity | Risk |
|---|---|---|
| Schema versioning with backward compatibility | Medium. Each schema version is explicit. Agents handle multiple versions | Low. Safest option |
| Re-execute from extraction on resume | Low complexity. Just re-run | Medium. Re-extraction might produce different results than the original, creating audit inconsistency |
| Schema migration on resume | High. Transform old checkpoint data to new schema | Medium. Migration logic itself can have bugs |
| Block deploys during open workflows | Low complexity. Just don’t deploy | High. Operationally unacceptable for pipelines with 72-hour review cycles |
The right answer for financial systems is schema versioning. Every intermediate result carries a schema_version field. Downstream agents accept a range of schema versions and handle the differences explicitly. When you deprecate an old schema version, you wait until all in-flight workflows using that version have completed or expired. This is operationally annoying but prevents silent data corruption.
{
"schema_version": "extraction_v3",
"doc_id": "INV-2026-03-12-0042",
"extracted_at": "2026-03-12T14:30:00Z",
"vendor": "Acme Corp",
"invoice_number": "ACM-2026-1234",
"currency_code": "USD",
"line_items": [
{
"description": "Widget Type A",
"quantity": 100,
"unit_price": 12.50,
"total": 1250.00,
"po_reference": "PO-2026-5678"
}
],
"tax": {"rate": 0.08, "amount": 100.00},
"total_amount": 1350.00,
"payment_terms": "NET30",
"due_date": "2026-04-11"
}Timeout Handling
Different steps have very different timeout profiles:
| Step | Expected Duration | Timeout | On Timeout |
|---|---|---|---|
| Extraction | 5-30 seconds | 10 minutes | Retry 2x, then dead-letter |
| Reconciliation | 1-5 seconds | 5 minutes | Retry 3x, then dead-letter |
| Compliance validation | 2-10 seconds | 5 minutes | Retry 2x, then dead-letter |
| Human review | Hours to days | 72 hours | Auto-escalate to manager, then auto-reject at 96 hours |
| Payment submission | 1-10 seconds | 15 minutes | Retry 5x with backoff, then dead-letter with high-priority alert |
The human review timeout deserves attention. Auto-rejecting after 72-96 hours sounds aggressive, but the alternative is documents sitting in a review queue indefinitely. In practice, you escalate at 72 hours (CC the reviewer’s manager, bump priority in the queue) and auto-reject at 96 hours. The auto-rejected document goes back to the ingestion queue for reprocessing. If it gets flagged again, it clearly needs manual attention, and the escalation path is more aggressive the second time.
Step 5: Multi-Agent Handoff and Parallel Validation
Structured Handoff Protocol
The agents in this pipeline don’t share a conversation. They pass structured intermediate results through the saga coordinator. This is deliberate. In a conversational multi-agent setup (like CrewAI or AutoGen’s default mode), agents communicate via natural language messages. That works for brainstorming. It doesn’t work when the Extraction Agent needs to pass a precise $1,250.00 amount to the Reconciliation Agent and you can’t afford the Reconciliation Agent misinterpreting it as $1,250 or $12,500.00 because the LLM reformatted the number.
The handoff protocol is a typed schema, not a message:
@dataclass
class ExtractionResult:
doc_id: str
schema_version: str
vendor: VendorInfo
invoice_number: str
line_items: list[LineItem]
tax: TaxInfo
total_amount: Decimal # Decimal, not float. Never float for money.
payment_terms: str
due_date: date
extraction_confidence: float # 0-1, field-level average
low_confidence_fields: list[str] # Fields where model confidence < 0.85
raw_model_output: str # For audit trail
@dataclass
class ReconciliationResult:
doc_id: str
schema_version: str
matched_po_id: str | None
match_type: MatchType # EXACT, FUZZY, MULTI_CANDIDATE, NO_MATCH
match_confidence: float
discrepancies: list[Discrepancy]
amount_variance: Decimal # Positive = invoice higher than PO
amount_variance_pct: float
candidate_pos: list[POCandidate] # All candidates considered, for auditThe Decimal type for monetary amounts is not pedantic. IEEE 754 floating point cannot represent $1,250.01 exactly. Over thousands of transactions, floating point rounding errors accumulate into real discrepancies that fail reconciliation checks. Every financial system uses fixed-point or decimal arithmetic for this reason.
Fan-Out: Parallel Compliance Validation
The Compliance Agent isn’t actually a single agent. It’s a fan-out to multiple specialized validators that run in parallel:
| Validator | What It Checks | Implementation | Typical Latency |
|---|---|---|---|
| Duplicate detector | Same vendor + same amount + within 30 days | Database query with composite index | Under 50ms |
| Three-way matcher | PO amount vs goods receipt vs invoice amount | Deterministic comparison with tolerance | Under 100ms |
| Tax validator | Tax rate and amount correct for jurisdiction | Rules engine (jurisdiction lookup table) | Under 100ms |
| Contract terms checker | Early payment discount applied correctly, net terms match contract | LLM for non-standard terms, rules engine for standard | 200ms-5s |
| Sanctions/embargo checker | Vendor not on OFAC or other restricted lists | API call to compliance service | 500ms-2s |
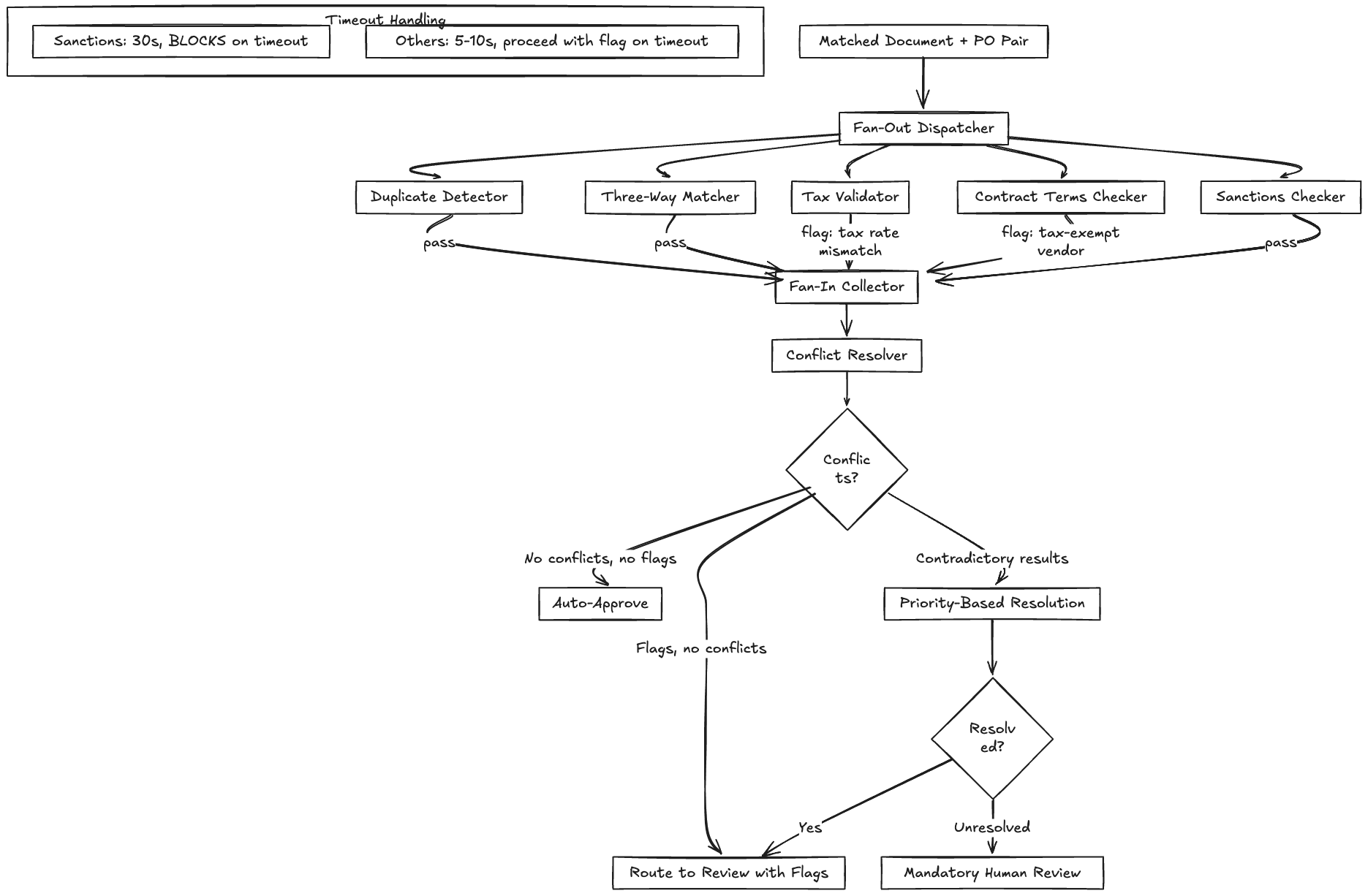
The fan-out runs all five validators in parallel. The fan-in collects results and resolves conflicts. Most of the time, there are no conflicts: 4 validators pass, maybe 1 flags something. The interesting case is contradictory results.
Example: the tax validator says the tax rate is correct (8% sales tax for California), but the contract terms checker found a clause in the vendor agreement that says this vendor has a tax-exempt status for certain categories. Both validators are correct based on their own scope. The tax validator checked the jurisdiction rules. The contract terms checker checked the vendor agreement.
Resolution logic for contradictory validators:
class ValidationResolver:
def resolve(self, results: list[ValidationResult]) -> ResolvedValidation:
# Priority ordering: sanctions > contract terms > three-way > tax > duplicate
# Higher priority validators override lower priority on conflicts
flags = []
for result in sorted(results, key=lambda r: r.priority, reverse=True):
for flag in result.flags:
conflicting = self.find_conflicting_flags(flag, flags)
if conflicting:
# Higher priority flag wins, but log the conflict
flag.conflicting_with = conflicting
flag.resolution = "higher_priority_override"
flags.append(flag)
# Any unresolved conflicts go to human review
unresolved = [f for f in flags if f.resolution == "unresolved"]
requires_review = len(unresolved) > 0 or any(
f.severity == "critical" for f in flags
)
return ResolvedValidation(
flags=flags,
requires_review=requires_review,
auto_approved=not requires_review and len(flags) == 0
)The priority ordering is a business decision, not a technical one. Sanctions checks always override everything else (legal requirement). Contract terms override standard tax rules (contractual obligation). Three-way match overrides individual component checks. This ordering should be configurable per organization, not hardcoded.
When the LLM Enters Reconciliation
Most PO matching is deterministic. The invoice says “PO-2026-5678” and there’s a purchase order with that exact number. Done. The LLM enters for three specific scenarios:
Scenario 1: Missing PO reference. The invoice doesn’t include a PO number (surprisingly common with smaller vendors). The Reconciliation Agent uses the vendor name, line item descriptions, amounts, and dates to find candidate POs. A text embedding similarity search over PO descriptions, combined with amount range filtering, produces a ranked list of candidates. If the top candidate has >0.9 similarity and the amount is within tolerance, it’s an auto-match. Otherwise, it goes to human review with the candidate list.
Scenario 2: Amended PO. The original PO was for 100 units at $12.50 each. The PO was later amended to 120 units at $12.00. The invoice is for 120 units at $12.00. The deterministic matcher finds the PO by number but flags a discrepancy on the unit price against the original PO amount. An LLM that can see the PO amendment history resolves this without human intervention: “PO was amended on Feb 15, 2026 to reflect new pricing. Invoice matches the amended terms.”
Scenario 3: Multi-line split. One invoice covers items from three different POs. The deterministic matcher finds partial matches but can’t resolve the split. The LLM maps each invoice line item to the correct PO based on item descriptions, quantities, and contextual clues in the document.
For scenarios 2 and 3, the LLM is called with a structured prompt that includes the invoice data, the candidate PO(s), and the amendment history. The output is constrained to a match decision schema:
{
"match_decision": "MATCHED_WITH_AMENDMENT",
"matched_po_id": "PO-2026-5678",
"amendment_reference": "AMD-2026-5678-02",
"explanation": "Invoice line items match PO amendment dated 2026-02-15",
"confidence": 0.94,
"discrepancies": []
}The confidence threshold for auto-matching via LLM is intentionally higher (0.9) than the deterministic matcher’s threshold (0.85). The LLM is a fallback, and fallbacks should have tighter quality gates.
Failure Modes
Financial pipelines have failure modes that don’t exist in conversational agents. Worth listing the ones that actually hurt in production:
1. Partial Saga with Failed Compensation
Covered in Step 3, but the remediation pattern matters. When compensation fails and retries exhaust, the dead-letter queue entry must contain:
- The full saga state at the point of failure
- Which compensation steps succeeded and which failed
- The specific error from each failed compensation attempt
- A recommended manual remediation action
The operations team needs to be able to look at a dead-letter entry and know exactly what state the document is in across all downstream systems. “Payment failed” is not enough. “Payment submission returned HTTP 503 from Chase API. PO reservation PO-2026-5678 was NOT released in SAP (compensation failed, SAP returned connection timeout). Extraction and validation records exist in document store.” That’s actionable.
2. Duplicate Document Processing
Two copies of the same invoice arrive through different channels (email and SFTP). Without deduplication, both flow through the pipeline and create two payment instructions.
The first line of defense is content hashing at ingestion. Hash the document content (after normalizing whitespace and encoding) and check against a dedup store. Same hash = same document, skip processing. But this misses near-duplicates: same invoice with a slightly different scan quality, or a PDF version vs an email-body version of the same invoice.
The second line is semantic deduplication at the extraction stage. After extraction, check for existing documents with the same vendor + invoice number + total amount + date combination. This catches format variants of the same invoice. The compound key (vendor + invoice number + amount + date) is more robust than any single field because vendors occasionally reuse invoice numbers across years.
3. Extraction Hallucination on Amounts
The Extraction Agent extracts $12,500.00 from an invoice that actually says $1,250.00. The LLM misread a comma-formatted number or hallucinated a digit. This is the highest-impact extraction failure because it flows through to a payment instruction for 10x the correct amount.
Mitigations:
- Cross-field validation: Total should equal sum of line items plus tax. If the extracted total doesn’t match the sum, flag for review
- Historical range check: This vendor’s invoices historically range from $500-$5,000. A $12,500 invoice is an outlier. Flag for review, don’t block
- Dual extraction: For invoices above a configurable threshold ($10,000), run extraction twice with different temperature settings or different models, and compare results. If they disagree on any amount field, route to human review
The dual extraction approach costs 2x on inference for high-value documents. At $0.03-0.05 per extraction, that’s an additional $0.05 per high-value document. Compare that to the cost of a $11,250 overpayment. The ROI is obvious.
4. Fan-Out Result Timeout
One of the five compliance validators hangs. The other four return in under a second. If you wait for all five before proceeding, one slow validator blocks the entire pipeline for that document. If you proceed without it, you might miss a critical compliance check.
The resolution: tiered timeouts based on validator criticality.
| Validator | Timeout | On Timeout |
|---|---|---|
| Sanctions checker | 30 seconds (extended) | BLOCK. Cannot proceed without sanctions clearance |
| Three-way matcher | 5 seconds | Proceed with flag. Likely a database issue, not a compliance risk |
| Tax validator | 5 seconds | Proceed with flag. Route to manual tax review |
| Duplicate detector | 5 seconds | Proceed with flag. Check duplicate status before payment step |
| Contract terms | 10 seconds | Proceed with flag. LLM-based, slower by nature |
The sanctions checker gets a longer timeout and blocks on failure because processing a payment to a sanctioned entity is a legal violation, not a business inconvenience. Every other validator can be handled with a flag and deferred review.
Operational Concerns
Dead-Letter Queue as a First-Class Surface
The dead-letter queue (DLQ) is not a logging bucket. It’s the primary operational interface for the pipeline team. In steady state, the DLQ should be near-empty. Any growth in DLQ depth is a leading indicator of system health issues.
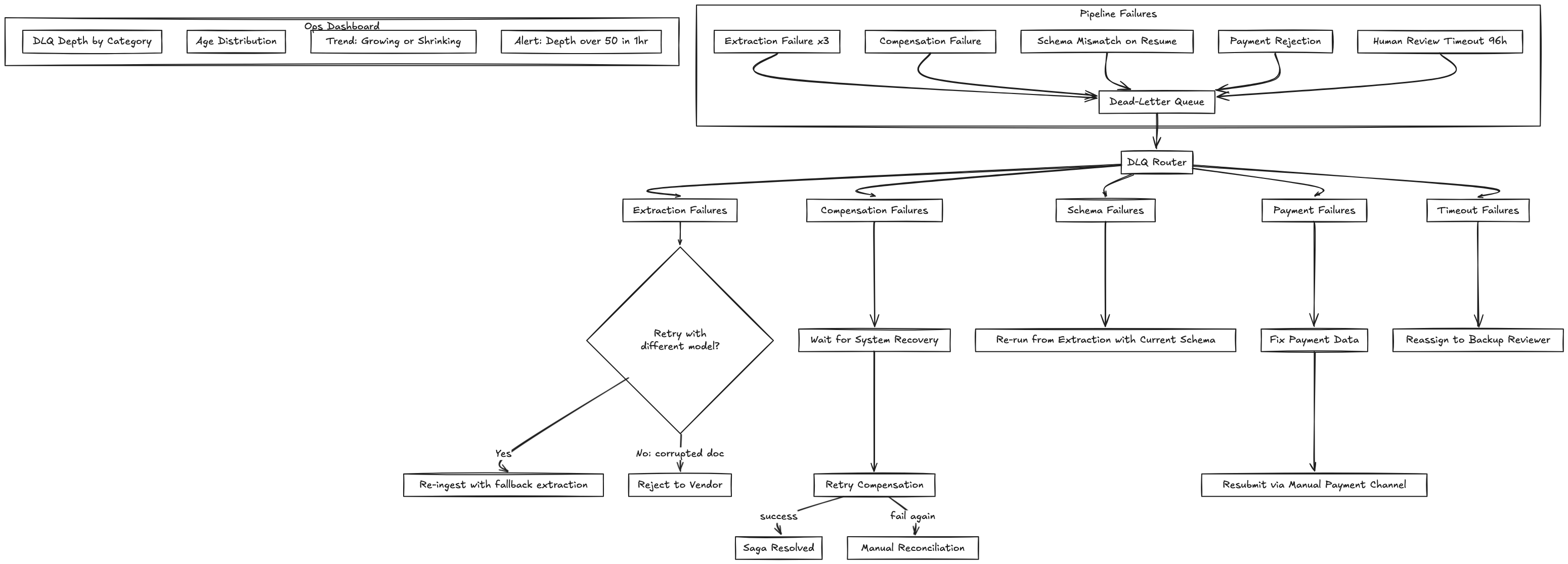
DLQ entries are categorized by failure type, and each type has a different remediation path:
| Failure Category | Typical Cause | Remediation |
|---|---|---|
| Extraction failure (repeated) | Corrupted document, unsupported format | Manual extraction or reject back to vendor |
| Compensation failure | Downstream system outage during rollback | Retry when system recovers, then reconcile manually |
| Schema mismatch on resume | Pipeline version deployed during open workflow | Re-run from extraction with current schema version |
| Payment rejection | Invalid bank details, insufficient funds, compliance hold | Fix data, resubmit through manual payment channel |
| Timeout escalation | Human reviewer didn’t act within SLA | Reassign to backup reviewer or auto-reject with notification |
The operations dashboard should show DLQ depth by category, age distribution (how long entries have been sitting), and trend (growing or shrinking). A DLQ depth that’s growing faster than the operations team can drain it is a production incident, not a backlog.
Observability
Standard application metrics (latency, error rate, throughput) are not sufficient for a saga-based pipeline. You need saga-level observability:
Per-document trace: Every document gets a trace ID at ingestion. Every agent step, every retry, every compensation, every human review decision is logged under that trace ID. When a finance controller asks “what happened to invoice ACM-2026-1234?”, you can pull the full trace in seconds.
Saga state distribution: At any point in time, how many documents are in each state? A healthy pipeline has most documents in “completed” or “processing,” with a small percentage in “awaiting_review.” If “awaiting_review” grows faster than reviews are completed, the human bottleneck will eventually cascade into the DLQ via timeouts.
Agent-level metrics:
| Metric | What it tells you |
|---|---|
| Extraction confidence distribution | Shift toward lower confidence means document quality is degrading or a new vendor format appeared |
| PO match rate (auto vs manual) | Drop in auto-match rate means PO data in ERP is stale or vendors changed invoice formats |
| Compliance flag rate by type | Spike in tax flags could mean a jurisdiction updated rates and the rules engine is stale |
| Payment success rate | Drop means downstream payment system issues, not pipeline issues |
| DLQ inflow rate by category | The best single metric for overall pipeline health |
Cost tracking: Break down cost per document across the pipeline:
| Component | Cost per Document | Notes |
|---|---|---|
| LLM extraction (frontier model) | $0.02-0.05 | Varies by page count. 80% of total inference cost |
| LLM reconciliation fallback | $0.005 | Only invoked for ~15% of documents |
| Compliance validation (mostly rules) | $0.001 | LLM used only for contract terms |
| Workflow engine (Temporal) | $0.001 | Per-workflow execution cost |
| Storage (document + intermediates) | $0.0005 | S3 + DynamoDB |
| Total (straight-through) | ~$0.03 | Without human review |
| Total (with human review) | ~$0.03 + human cost | Human cost dominates when review is needed |
The insight from this breakdown: extraction is 80% of the inference cost. If you want to reduce cost, improve extraction accuracy to reduce re-extractions and human review routing. Switching the reconciliation or compliance agents to a cheaper model saves almost nothing.
Alerting Priority
In order of urgency:
- DLQ depth growing (>50 entries over 1 hour). Something systemic is failing. Check downstream system health first.
- Payment rejection rate >1%. Possible schema change in banking API, or vendor data quality issue.
- Straight-through processing rate dropping below 65%. More documents routing to human review than expected. Check extraction confidence and compliance flag distributions.
- Extraction confidence P50 dropping. A new vendor format or document quality issue. Usually precedes a drop in straight-through rate by 1-2 days.
- Human review queue age P90 >48 hours. Reviews are backing up. Escalate staffing before the 72-hour timeout starts auto-rejecting.
- Saga duration P95 >30 minutes for straight-through cases. Performance degradation somewhere in the pipeline. Check LLM latency and database query times.
Scaling for Month-End Close
Month-end close is the surge event. Document volume spikes 3-5x for 3-5 business days. The pipeline needs to handle this without manual scaling intervention.
The bottleneck during month-end is almost never LLM inference (extraction at 200 documents/hour is well within a single GPU’s capacity). The bottleneck is human review queue depth. If 30% of documents need review during normal operations and volume triples, the review queue triples. But reviewer capacity doesn’t triple.
Practical mitigations:
- Lower the extraction confidence threshold for auto-processing during month-end (from 0.95 to 0.90). This sends more documents through without review, accepting a slightly higher error rate to clear the volume. The risk is managed by the downstream three-way match, which catches most extraction errors before payment.
- Pre-warm the PO cache: Many month-end invoices match POs created earlier in the month. Pre-loading active POs into the reconciliation cache before month-end reduces PO lookup latency and improves auto-match rates.
- Batch similar documents: If 50 invoices from the same vendor arrive on the same day, batch them for review rather than presenting each individually. The reviewer sees the batch with extracted data side by side, approving or flagging much faster than individual review.
Going Deeper
A few topics for staff+ level discussions:
Event sourcing for the document ledger: Instead of storing the current state of each document, store the sequence of events (ingested, extracted, matched, validated, approved, paid). The current state is derived by replaying events. This makes the audit trail inherent in the data model rather than a separate logging concern. The trade-off is query complexity: answering “show me all documents awaiting review” requires a projection that may lag behind the event stream. For financial systems where audit is a regulatory requirement, event sourcing is worth the complexity.
Multi-region document processing: If the enterprise operates across regions with data residency requirements (GDPR in EU, data localization in certain Asian markets), documents from EU vendors may need to be processed on EU infrastructure. The saga coordinator needs to route extraction and storage to the correct regional infrastructure while maintaining a global view of document status. This is a deployment topology concern, not an agent design concern, but it affects how you partition the saga state store.
LLM-as-judge for extraction quality: Instead of (or in addition to) cross-field validation, use a second LLM call to review the extraction output against the original document. The judge prompt asks: “Given this document image and this extracted JSON, are all amounts correct? Are any fields missing?” This catches errors that cross-field validation misses (correct sum but wrong line item breakdown). The cost is an additional $0.02-0.03 per document, which is justified for high-value invoices.
Handling multi-currency invoices: When a vendor invoices in EUR but payment is in USD, the extraction needs to capture the original currency and amount. The Payment Agent applies the exchange rate at payment time, not extraction time (rates change). This means the total amount validated during compliance may differ from the total paid by the exchange rate delta. The three-way match tolerance needs to account for currency conversion variance, typically 1-2% wider tolerance for cross-currency invoices.
References
[1] Temporal — Durable Execution Platform
[2] Anthropic — Building Effective Agents
[3] Stripe — Idempotent Requests
[4] Microsoft — Saga Pattern in Microservices
[5] AWS — Step Functions for Long-Running Workflows
[6] Restate — Durable Execution Engine
[7] Martin Kleppmann — Designing Data-Intensive Applications (Event Sourcing)
[8] Chris Richardson — Saga Pattern
[10] SOX Compliance — Financial Controls
Note: This blog represents my technical views and production experience. I use AI-based tools to help with drafting and formatting to keep these posts coming daily.
← Back to all posts