Case Study: Building an Adaptive Code Review Agent with Learning Feedback Loops
Table of contents
- #Problem Statement
- #Step 0: Why GenAI?
- #Step 1: Requirements
- #Step 2: Architecture
- #Step 3: Three-Tier Memory Architecture
- #Step 4: Adaptive Routing and Online Learning
- #Step 5: Confidence Calibration and Comment Gating
- #Step 6: Review Planning for Large PRs
- #Failure Modes
- #Operational Concerns
- #Going Deeper
- #References
This post applies the 9-step case study structure from the GenAI System Design Framework.
Problem Statement
A large engineering organization ships 2,000-4,000 pull requests per week across 50+ teams. Every PR needs review. Senior engineers spend 5-10 hours per week reviewing code, and the quality of reviews varies enormously. Some reviewers catch subtle concurrency bugs. Others rubber-stamp everything. Review latency (time from PR opened to first substantive review comment) averages 8-12 hours, and that number gets worse during crunch periods when everyone’s busy shipping.
Automated tooling exists: linters, static analysis, type checkers. These catch syntactic issues and known anti-patterns. They don’t catch architectural concerns, subtle logic errors, performance pitfalls specific to the codebase, or violations of unwritten team conventions that exist in senior engineers’ heads but nowhere in documentation.
What we’re building: an agent that reviews pull requests, posts comments on potential issues, and adapts its behavior based on whether reviewers accept or dismiss those comments. Not a linter. Not a static analysis tool. An agent that learns what each team cares about and calibrates its confidence to avoid comment fatigue.
Primary users: PR authors who see the agent’s review comments alongside human reviews.
Secondary users: human reviewers who accept or dismiss agent comments (providing the feedback signal), and engineering managers who monitor adoption and value metrics.
What This System Is Not
This is not a replacement for human code review. Human reviewers catch design issues, question architectural decisions, and provide mentorship. The agent handles the repetitive pattern-matching that experienced reviewers do reflexively: “this database call inside a loop will be slow,” “this error isn’t being propagated,” “this concurrency pattern has a known race condition.” The agent frees human reviewers to focus on higher-order concerns.
It’s also not a code generation or auto-fix system. It posts comments identifying potential issues. It doesn’t push fix commits. The PR author decides whether to address the comment, and the human reviewer decides whether the comment was valuable (by accepting or dismissing it in the review interface). That feedback signal is what makes the system adaptive.
Step 0: Why GenAI?
Static analysis tools catch issues defined by rules. If you can write a rule for it (unused variable, missing null check, SQL injection pattern), a linter handles it faster and cheaper than an LLM. The LLM is justified for the class of issues that require understanding context, intent, and the codebase’s specific patterns.
Examples of things linters catch well:
- Unused imports, dead code, formatting violations
- Known vulnerability patterns (SQL injection, XSS)
- Type errors, null safety violations
- Cyclomatic complexity thresholds
Examples of things that require contextual understanding:
- “This service always uses optimistic locking for concurrent updates, but this new endpoint uses pessimistic locking. Was that intentional?”
- “The retry logic here doesn’t have jitter. In this service, that caused a thundering herd during the March incident.”
- “This query will scan the full table. The users table has 50M rows. You need an index on created_at.”
- “This function mutates its input argument. Every other function in this module returns a new copy. This inconsistency will confuse the next person who reads it.”
These require knowing the codebase’s conventions, the team’s history, and the production context. That knowledge lives in senior engineers’ heads. The goal of the memory architecture (Step 3) is to capture some of it in a form the agent can use.
Cost math: an LLM review of a medium PR (300-500 changed lines) costs roughly $0.10-0.30 in inference. A senior engineer’s review time is worth $75-150/hour, and a typical review takes 15-30 minutes. If the agent catches even one issue per 5 PRs that would have otherwise reached production, the ROI is strongly positive. The real question is not cost but trust: will developers actually read and act on the agent’s comments?
Step 1: Requirements
Functional Requirements
- Review every PR opened against the main branch (or configured target branches)
- Identify potential issues: bugs, performance problems, security concerns, convention violations, readability issues
- Post inline comments on specific code lines with the issue description and severity
- Accept feedback: reviewers can accept (thumbs up) or dismiss (thumbs down) each comment
- Adapt routing and confidence thresholds based on accumulated feedback
- Support team-specific conventions without per-team fine-tuning
Non-Functional Requirements
- Latency: First review comments posted within 5 minutes of PR creation. Developers expect quick feedback. If the agent takes 30 minutes, the developer has moved on.
- Precision: Over 70% of posted comments should be accepted (not dismissed) by reviewers. Below this threshold, developers start ignoring the agent entirely. Comment fatigue is the primary adoption risk.
- Recall vs precision trade-off: Strongly favor precision. A missed issue is invisible. A wrong comment is visible, annoying, and erodes trust. Better to catch 40% of issues with 80% precision than 80% of issues with 50% precision.
- Availability: 99% uptime. Missing a review is not critical (human reviewers are still there). Posting wrong reviews during a degraded state is worse than posting nothing.
Scale Assumptions
| Metric | Value |
|---|---|
| PRs per week | 2,000-4,000 |
| Average changed lines per PR | 200-500 |
| Code hunks per PR (reviewable units) | 5-20 |
| Teams | 50+ |
| Languages | 4-6 primary (Go, Python, TypeScript, Java, Terraform, SQL) |
| Comments posted per PR (target) | 0-3 high-confidence comments |
| Feedback signals per week | 3,000-8,000 accept/dismiss signals |
The inference load is moderate: 2,000-4,000 reviews per week, each requiring analysis of 5-20 code hunks. At $0.10-0.30 per review, weekly inference cost is $200-1,200. The interesting scaling challenge is not compute but memory: consolidating feedback signals from 50+ teams into actionable team-specific conventions.
Quality Metrics
| Metric | Target | Why this number |
|---|---|---|
| Comment acceptance rate | Over 70% | Below this, developers tune out the agent |
| Mean time to first comment | Under 5 minutes | Developer attention window |
| False positive rate (dismissed comments) | Under 30% | Directly determines adoption |
| Issue catch rate (estimated) | Over 30% of reviewable issues | Hard to measure directly, estimated from accepted comments vs total human review comments |
| Comment fatigue signal | Under 2 dismissed comments per PR average | More than 2 dismissals per PR and developers stop reading |
Trade-offs to Acknowledge
| Trade-off | Option A | Option B | Our lean |
|---|---|---|---|
| Aggressive commenting (high recall) vs conservative (high precision) | Catch more issues, more noise | Fewer comments, higher trust | Option B. Trust is harder to rebuild than recall is to increase |
| Online learning speed vs stability | Fast adaptation to new feedback | Resistant to single-reviewer bias | Slow adaptation. 20+ signals before updating weights |
| Per-team fine-tuning vs shared model with retrieval | Better behavioral fit, high maintenance | One model, team conventions via memory | Shared model + retrieval. Fine-tuning 50 models is operationally unsustainable |
| Memory consolidation frequency | Frequent: overfit recent trends | Infrequent: miss convention changes | Weekly consolidation with decay on old patterns |
Step 2: Architecture
The Review Pipeline
A PR webhook triggers the pipeline. The agent doesn’t review the entire PR as a monolith. It breaks the PR into code hunks (logical change units, roughly corresponding to file-level diffs) and routes each hunk to the appropriate specialist sub-agent.
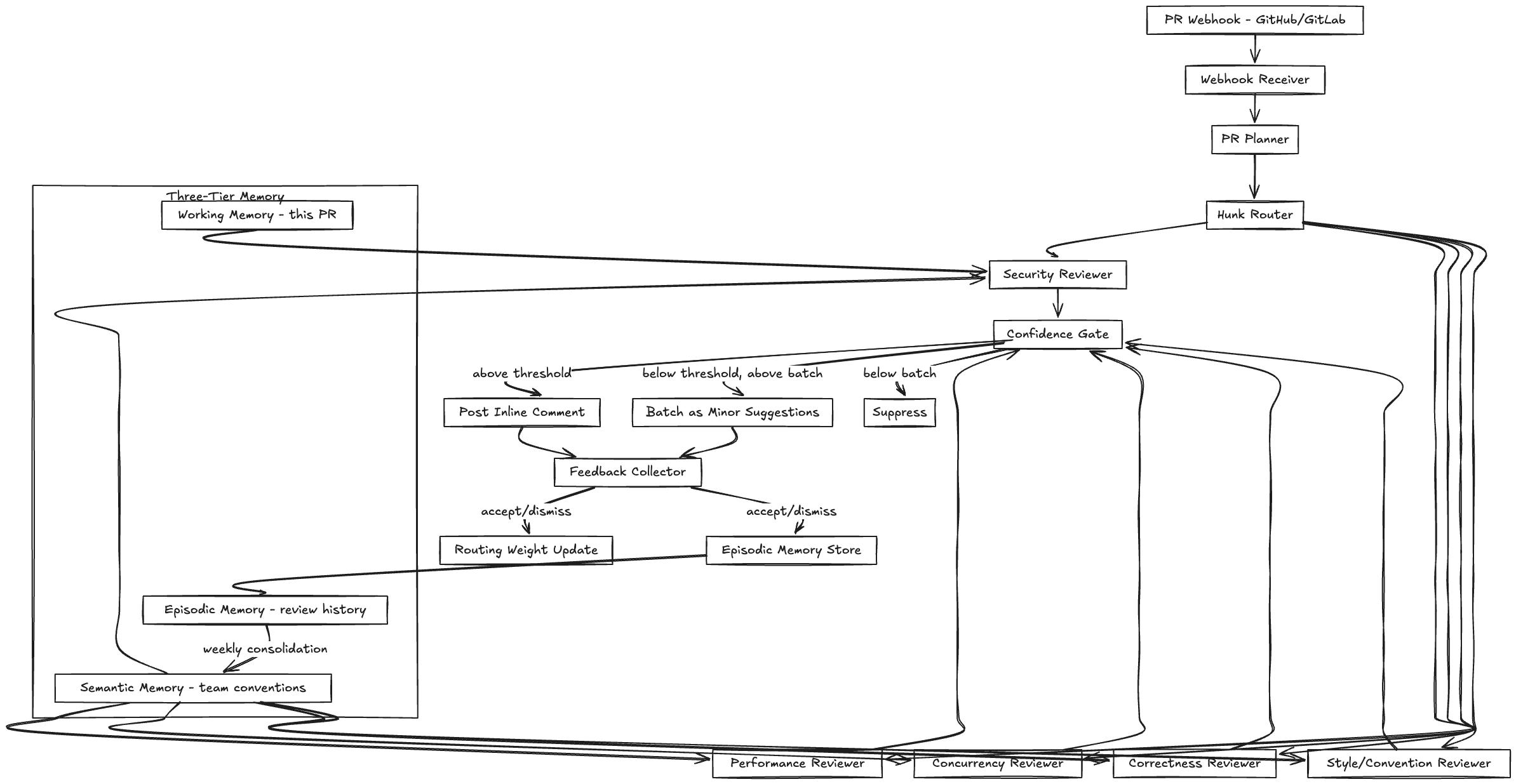
Webhook Receiver: Listens for PR opened/updated events from GitHub/GitLab. Extracts the diff, changed file list, PR metadata (author, team, target branch).
PR Planner: For small PRs (under 200 changed lines), review all hunks. For large PRs (200+ changed lines), plan the review order based on file criticality and change type. Review infrastructure configs and data model changes first, test file changes last.
Hunk Router: Routes each code hunk to one or more specialist sub-agents based on file type, change content, and team-specific routing weights. The routing weights are the adaptive component, updated by feedback signals.
Sub-Agents (specialist reviewers):
| Sub-Agent | Focus Area | When Routed |
|---|---|---|
| Security Reviewer | Auth, input validation, secrets, injection | Files touching auth, API handlers, user input |
| Performance Reviewer | N+1 queries, unbounded loops, missing indexes, memory leaks | Database queries, hot path code, data processing |
| Concurrency Reviewer | Race conditions, deadlocks, shared state | Goroutines, async/await, thread pools, distributed locks |
| Correctness Reviewer | Logic errors, edge cases, error handling | Business logic, state machines, conditional branches |
| Style/Convention Reviewer | Team-specific patterns, naming, architecture consistency | Everything (but lowest priority, most likely to be suppressed) |
Memory Store: Three-tier memory system (detailed in Step 3) that provides team conventions, past review patterns, and current PR context to each sub-agent.
Confidence Gate: Before posting any comment, evaluate confidence against the team’s acceptance threshold. Suppress low-confidence comments or batch them into a single “minor suggestions” thread.
Feedback Collector: Captures accept/dismiss signals from the review interface and feeds them back into the routing weights and memory consolidation pipeline.
Why Sub-Agents Instead of One Reviewer?
The single-model approach fails the same way it fails in the logistics case study: a model with too many concerns in its prompt misses nuanced issues in each area. A security reviewer needs a different system prompt, different few-shot examples, and different evaluation criteria than a performance reviewer. The security reviewer looks for input validation gaps and auth bypass patterns. The performance reviewer looks for O(n^2) loops and missing database indexes. Combining them into one prompt dilutes both.
| Single Reviewer | Specialist Sub-Agents | |
|---|---|---|
| Prompt focus | Broad, tries to cover everything | Narrow, deep expertise per area |
| False positive rate | Higher (model hedges across many categories) | Lower (each agent is calibrated for its specific domain) |
| Routing cost | None (one model sees everything) | Small (router classifies file type + change content) |
| Per-team customization | One set of conventions for all review types | Team-specific memory per review category |
| Failure isolation | One bad prompt update affects all review types | Can disable or retune one sub-agent without affecting others |
The routing cost is negligible. Classifying a file into review categories is a simple rule-based decision (file extension + directory path + import analysis), not an LLM call. The Performance Reviewer only sees files that touch database queries or hot-path code. It doesn’t waste tokens analyzing test helpers or README changes.
Step 3: Three-Tier Memory Architecture
This is the core differentiator of the system. Without memory, the agent reviews every PR from scratch. It doesn’t know that team A always uses optimistic locking, that team B had a production incident from unbounded retries last month, or that the payments module has a specific pattern for handling idempotency. Senior human reviewers carry this context effortlessly. The agent needs it explicitly.
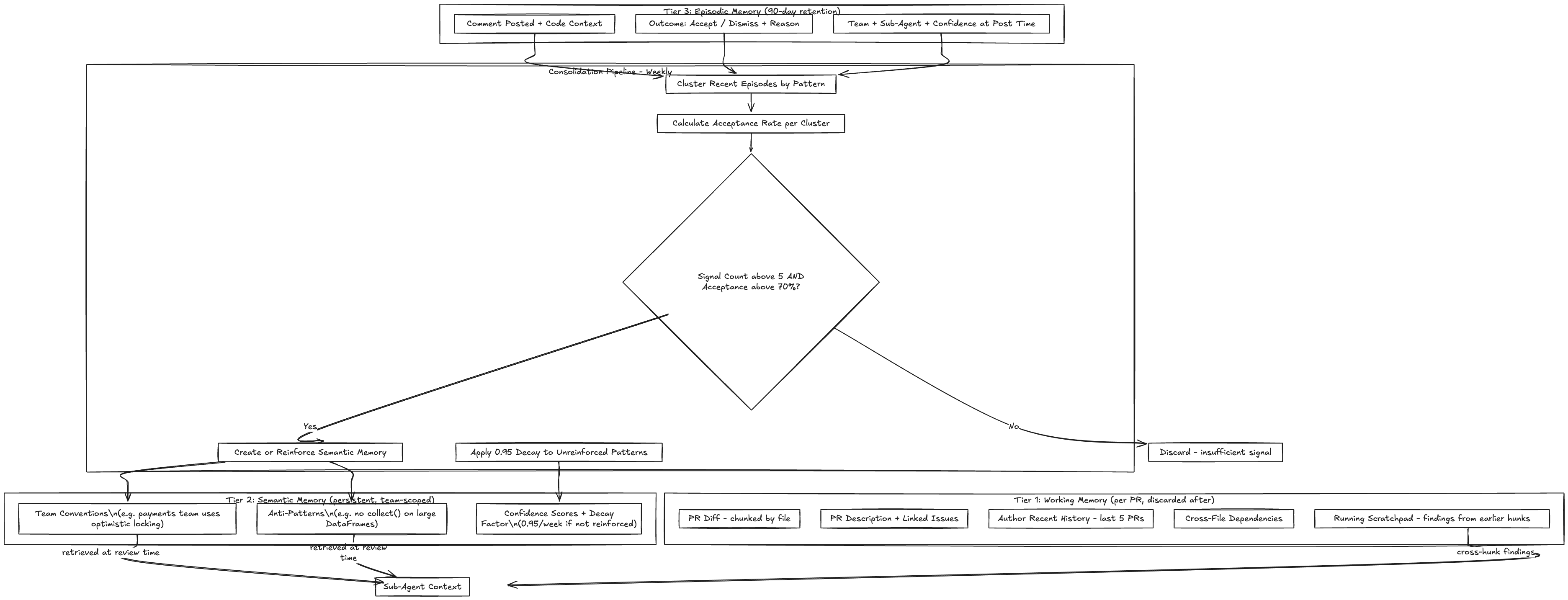
Tier 1: Working Memory (This PR)
Scope: the current PR being reviewed. Discarded after the review is posted.
Contents:
- Full PR diff (chunked by file)
- PR description and linked issues
- Author’s recent PR history (last 5 PRs, to understand their experience level with this part of the codebase)
- Dependencies between changed files (file A imports module from file B, both changed)
- Running analysis scratchpad (findings from earlier hunks that inform later hunks)
The scratchpad is important for large PRs. If the Concurrency Reviewer finds a shared mutex in file A, and file B (reviewed later) accesses the same shared state without holding that mutex, the scratchpad carries that context forward. Without it, the agent reviews each hunk in isolation and misses cross-file issues.
@dataclass
class WorkingMemory:
pr_diff: dict[str, FileDiff]
pr_metadata: PRMetadata
author_history: list[RecentPR]
file_dependencies: dict[str, list[str]]
scratchpad: list[Finding] # Accumulated across hunks
def add_finding(self, finding: Finding):
self.scratchpad.append(finding)
def get_relevant_context(self, current_file: str) -> list[Finding]:
"""Return findings from other files that are relevant to current_file."""
related_files = self.file_dependencies.get(current_file, [])
return [
f for f in self.scratchpad
if f.file_path in related_files
]Tier 2: Semantic Memory (Team Knowledge)
Scope: consolidated knowledge about each team’s conventions, patterns, and common issues. Persists across PRs. Updated weekly through memory consolidation.
This is where the agent’s “institutional knowledge” lives. It’s not hand-written documentation (though it can be seeded from it). It’s derived from patterns observed across thousands of reviews and feedback signals.
Examples of semantic memory entries:
{
"team": "payments",
"category": "concurrency",
"pattern": "All database writes in the payments service use optimistic locking with version columns. Pessimistic locking (SELECT FOR UPDATE) is avoided due to deadlock incidents in Q4 2025.",
"confidence": 0.92,
"source_signal_count": 47,
"last_updated": "2026-03-07",
"decay_factor": 0.95
}{
"team": "data-platform",
"category": "performance",
"pattern": "Spark jobs in the ETL pipeline must not use collect() on DataFrames with more than 10K rows. Use write to intermediate Parquet instead. Three incidents in 2025 from OOM on collect().",
"confidence": 0.88,
"source_signal_count": 23,
"last_updated": "2026-02-20",
"decay_factor": 0.95
}Each semantic memory entry has:
- Team scope: which team this applies to
- Category: maps to sub-agent routing (concurrency, performance, security, etc.)
- Pattern: the convention or anti-pattern in natural language
- Confidence: how reliable this pattern is, based on feedback signal count and acceptance rate
- Decay factor: applied weekly. Patterns that aren’t reinforced by new feedback signals gradually lose confidence. This prevents stale conventions from persisting indefinitely
Tier 3: Episodic Memory (Review History)
Scope: specific past reviews and their outcomes. Used for calibration and for detecting recurring issues.
Episodic memory records:
- Comment posted: what the agent said, on what code, for which PR
- Outcome: accepted or dismissed
- Context: team, file type, sub-agent that generated it, confidence at time of posting
- Timestamp: for recency weighting
This is the raw data that feeds into semantic memory consolidation and routing weight updates. It’s also used directly for calibration: “The last 20 times I flagged an unbounded retry in team X’s code, 18 were accepted and 2 were dismissed. My precision for this pattern on this team is 90%.”
Episodic memory has a retention window. Individual review records older than 90 days are dropped. The patterns they contributed to are already consolidated into semantic memory by then. Keeping them indefinitely wastes storage and, worse, anchors the agent to old conventions that may have changed.
Memory Consolidation
The consolidation pipeline runs weekly. It processes the episodic memory from the past week and updates semantic memory.
class MemoryConsolidator:
def consolidate_weekly(self, team: str):
# Fetch recent episodic memories for this team
recent_episodes = self.episodic_store.get_recent(
team=team, days=7
)
# Group by category and pattern similarity
clusters = self.cluster_episodes(recent_episodes)
for cluster in clusters:
acceptance_rate = cluster.accepted_count / cluster.total_count
existing = self.semantic_store.find_similar(
team=team,
category=cluster.category,
pattern=cluster.pattern_summary
)
if existing:
# Reinforce existing pattern
existing.confidence = self.update_confidence(
existing.confidence,
acceptance_rate,
cluster.total_count
)
existing.source_signal_count += cluster.total_count
existing.last_updated = datetime.now()
self.semantic_store.update(existing)
else:
# New pattern discovered
if cluster.total_count >= 5 and acceptance_rate > 0.7:
self.semantic_store.create(
team=team,
category=cluster.category,
pattern=cluster.pattern_summary,
confidence=acceptance_rate,
source_signal_count=cluster.total_count
)
# Apply decay to all patterns not reinforced this week
self.semantic_store.apply_decay(team=team, decay_factor=0.95)The minimum signal threshold (5 episodes) before creating a new semantic memory prevents single-instance patterns from polluting the knowledge base. The 0.7 acceptance rate threshold ensures only validated patterns are promoted.
Memory Poisoning Prevention
A single dismissive reviewer can bias the agent’s memory for an entire team. If one person always dismisses concurrency comments (maybe they don’t care about race conditions, or maybe they just hate agent comments), the agent learns to suppress concurrency warnings for that team.
Mitigations:
| Risk | Mitigation |
|---|---|
| Single reviewer dominating feedback | Weight feedback by reviewer diversity. A signal confirmed by 3 different reviewers counts more than 3 signals from 1 reviewer |
| Reviewer dismissing valid comments due to phrasing, not substance | Track dismiss reasons. “Not an issue” vs “Already addressed” vs “Too noisy” are different signals |
| Convention change (team adopted new pattern) | Decay factor gradually reduces confidence in old patterns. New signals from new pattern will eventually dominate |
| Sabotage (someone systematically dismisses to degrade the agent) | Rate-limit feedback influence per reviewer. No single person can change routing weights by more than 10% in a week |
The reviewer diversity weighting is the most important safeguard. In the confidence update formula:
def update_confidence(self, current: float, new_rate: float, signal_count: int) -> float:
# Weight by unique reviewers, not total signals
unique_reviewers = self.count_unique_reviewers(signals)
reviewer_weight = min(unique_reviewers / 3.0, 1.0) # Full weight at 3+ reviewers
blended = (current * 0.7) + (new_rate * 0.3 * reviewer_weight)
return max(0.1, min(0.99, blended)) # Clamp to [0.1, 0.99]A pattern needs agreement from at least 3 different reviewers to fully update its confidence. Fewer reviewers means the update is dampened.
Step 4: Adaptive Routing and Online Learning
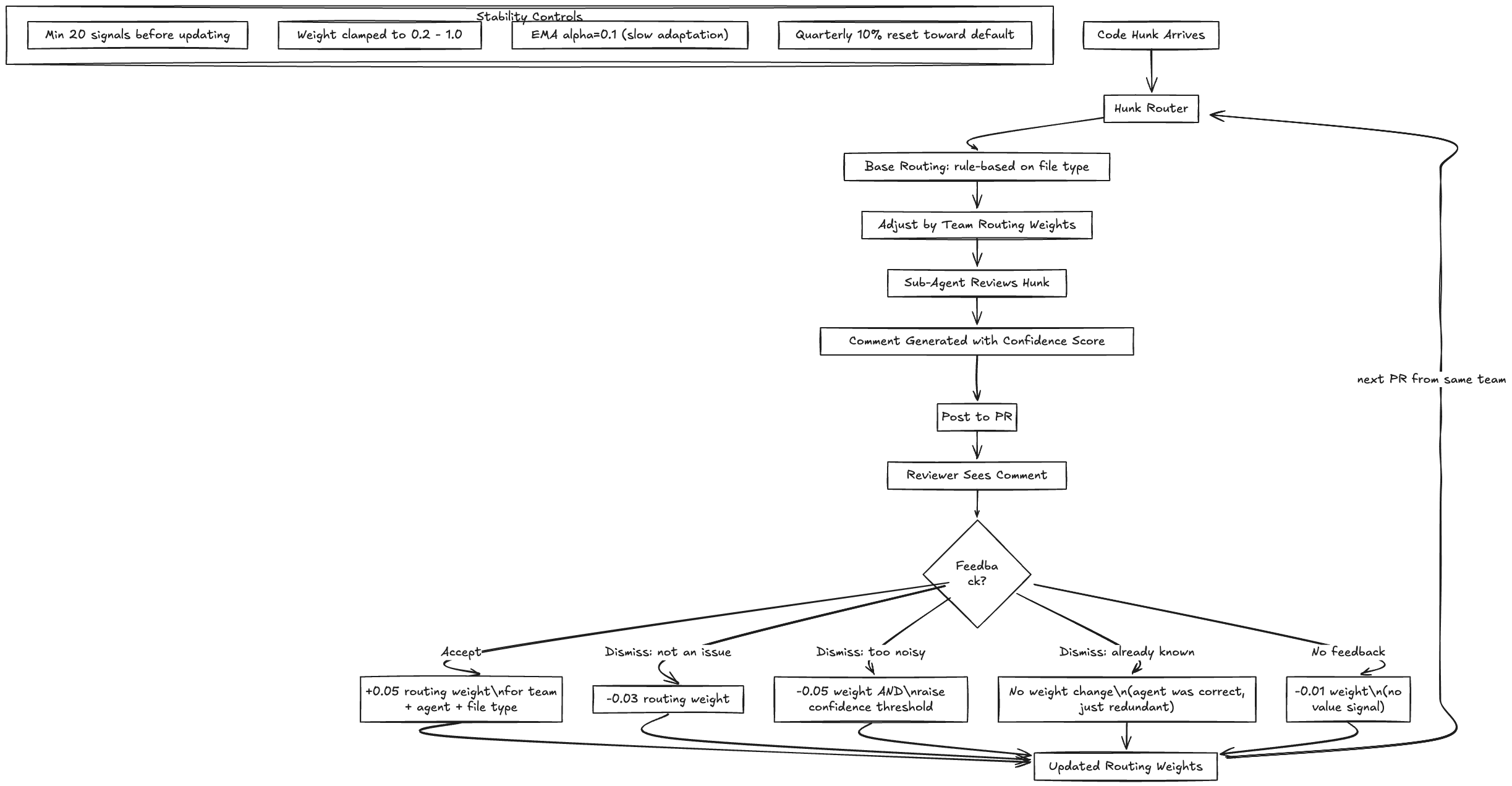
How Routing Works
When a code hunk arrives for review, the Hunk Router decides which sub-agents should review it. The base routing is rule-based (SQL file goes to Performance Reviewer, auth handler goes to Security Reviewer). The adaptive layer adjusts the routing probability based on feedback history.
class HunkRouter:
def route(self, hunk: CodeHunk, team: str) -> list[SubAgent]:
# Base routing: rule-based on file type and content
base_agents = self.rule_based_route(hunk)
# Adaptive adjustment: check feedback-weighted scores
adjusted = []
for agent in base_agents:
weight = self.get_routing_weight(
team=team,
agent=agent.name,
file_type=hunk.file_type
)
if weight > self.suppression_threshold: # Default: 0.3
adjusted.append((agent, weight))
# Also check if any non-base agents should be added
# (team-specific routing learned from feedback)
for agent in self.all_agents:
if agent not in base_agents:
team_weight = self.get_team_specific_weight(
team=team, agent=agent.name
)
if team_weight > self.promotion_threshold: # Default: 0.6
adjusted.append((agent, team_weight))
return [agent for agent, weight in adjusted]The routing weights are updated based on feedback:
| Feedback Signal | Weight Update |
|---|---|
| Comment accepted | Increase routing weight for that sub-agent + team + file type combination by 0.05 |
| Comment dismissed (“not an issue”) | Decrease routing weight by 0.03 |
| Comment dismissed (“already known”) | No weight change (agent was correct, just redundant) |
| Comment dismissed (“too noisy”) | Decrease weight by 0.05 and increase confidence threshold for that category |
| No comments posted (agent routed but found nothing) | Slight decrease by 0.01 (avoid wasting inference on hunks that never produce comments) |
The asymmetry is deliberate: it takes more positive signals to increase routing than negative signals to decrease it. This is because false positives (unnecessary comments) are more costly to developer trust than false negatives (missed issues). The system is biased toward conservative commenting.
Learning Rate and Stability
The routing weights need to change slowly. If a single bad week of reviews causes a large weight shift, the agent becomes unstable. A team has a week of reviewing trivial PRs where the Concurrency Reviewer posts no useful comments. The routing weight drops. Next week, a complex concurrent system change comes in, and the Concurrency Reviewer has been partially suppressed. It misses a real issue.
Stabilization mechanisms:
- Minimum signal threshold: No weight update until 20+ feedback signals have accumulated for a given team + agent + file type combination. Below this, use the default weight.
- Weight clamp: Routing weights are clamped to [0.2, 1.0]. No sub-agent is ever fully suppressed (0.2 minimum means it still reviews 20% of the time, providing ongoing calibration data). And no sub-agent is over-weighted above 1.0.
- Momentum term: Weight updates use exponential moving average with alpha=0.1, meaning 90% of the weight comes from historical values and only 10% from the new signal batch.
- Periodic reset: Every quarter, all weights decay 10% toward the default (0.5). This prevents long-term drift from locking the system into a local optimum.
Step 5: Confidence Calibration and Comment Gating
The Comment Fatigue Problem
The biggest risk to a code review agent is not inaccuracy. It’s noise. Developers who receive 5 unhelpful comments per PR learn to ignore all agent comments, including the one that would have caught a real bug. Comment fatigue is the primary adoption killer.
The solution is aggressive confidence gating: only post comments where the agent is confident enough that the comment will be accepted. The threshold varies by team (teams with higher tolerance for agent comments get a lower threshold) and by severity (a potential security vulnerability has a lower posting threshold than a style suggestion).
The Confidence Model
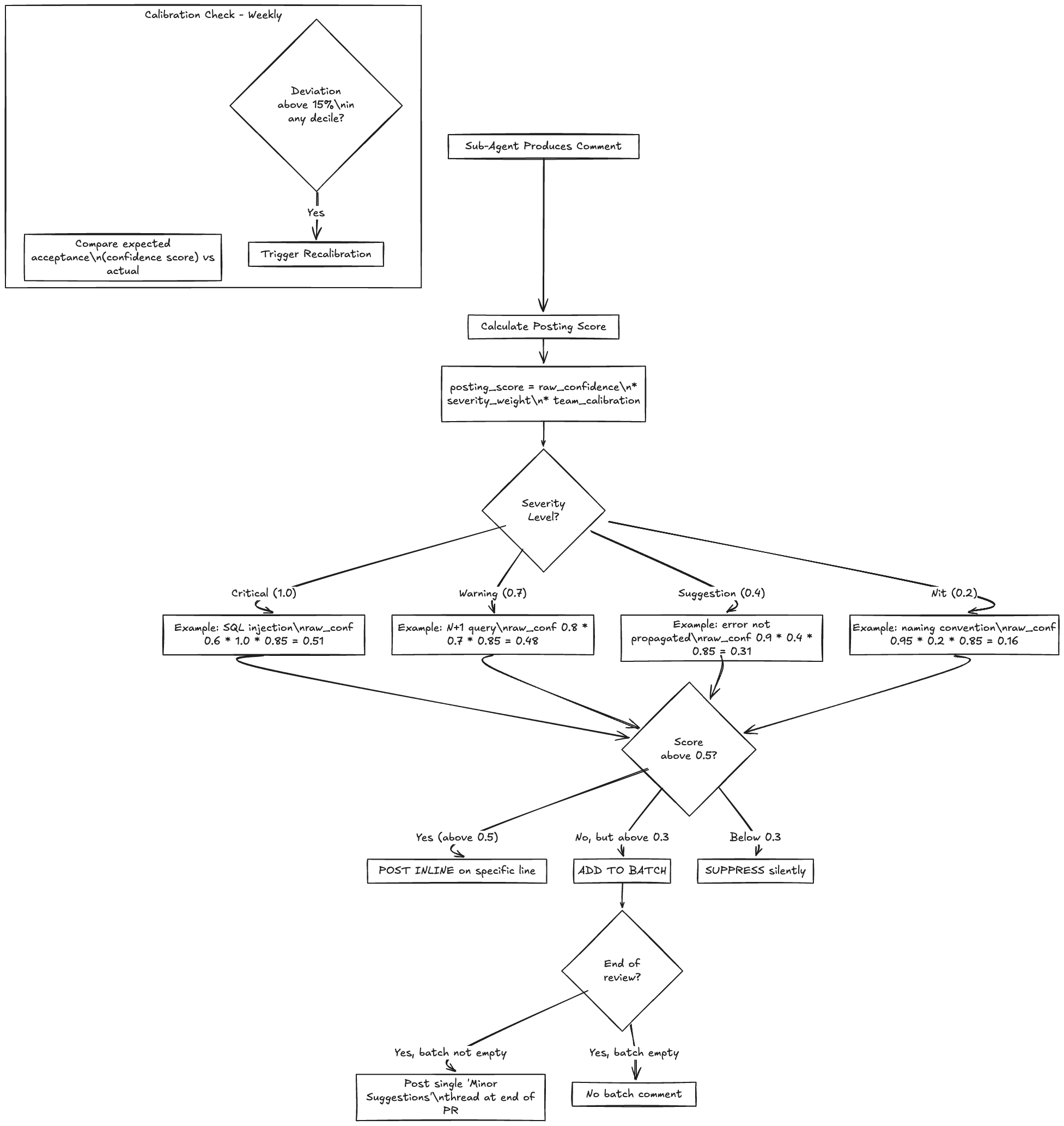
Each sub-agent produces a comment with a raw confidence score. The confidence gate transforms this into a posting decision using three factors:
posting_score = raw_confidence * severity_weight * team_calibration| Factor | What it captures |
|---|---|
| Raw confidence | How sure the sub-agent is that this is a real issue (0-1) |
| Severity weight | Critical (1.0), Warning (0.7), Suggestion (0.4), Nit (0.2) |
| Team calibration | Historical acceptance rate for this team + sub-agent combination |
The posting threshold is 0.5 by default. A critical security finding with 0.6 raw confidence posts (0.6 * 1.0 * team_cal). A nit-level style suggestion needs very high raw confidence to post (0.95 * 0.2 * team_cal = 0.19 * team_cal, which usually doesn’t clear the threshold). This naturally suppresses low-value comments without explicit rules.
Batching Low-Confidence Comments
Comments that fall below the individual posting threshold but above a batch threshold (0.3) are collected and posted as a single “Minor suggestions” comment thread at the end of the review. This gives the developer the option to read them without cluttering the diff view with inline comments they didn’t ask for.
class ConfidenceGate:
def __init__(self, team: str):
self.post_threshold = 0.5
self.batch_threshold = 0.3
self.team_cal = self.load_team_calibration(team)
self.pending_batch = []
def evaluate(self, comment: ReviewComment) -> PostingDecision:
score = (
comment.raw_confidence
* comment.severity.weight
* self.team_cal.get(comment.sub_agent, 0.5)
)
if score >= self.post_threshold:
return PostingDecision.POST_INLINE
elif score >= self.batch_threshold:
self.pending_batch.append(comment)
return PostingDecision.BATCH
else:
return PostingDecision.SUPPRESS
def flush_batch(self) -> ReviewComment | None:
if len(self.pending_batch) > 0:
return self.compose_batch_comment(self.pending_batch)
return NoneCalibration Drift Detection
The confidence model’s accuracy degrades over time as the codebase evolves, teams change, and conventions shift. A well-calibrated model posts comments at 0.7 confidence and sees 70% acceptance. If acceptance drops to 50% at the same confidence level, the model is miscalibrated.
Detection: weekly check of expected acceptance rate (the confidence score) vs actual acceptance rate, binned by confidence decile. If any decile deviates by more than 15 percentage points, trigger recalibration.
def check_calibration(self, team: str) -> CalibrationReport:
episodes = self.episodic_store.get_recent(team=team, days=30)
# Bin by confidence decile
bins = defaultdict(list)
for ep in episodes:
decile = int(ep.confidence * 10)
bins[decile].append(ep.accepted)
miscalibrated = []
for decile, outcomes in bins.items():
expected_rate = decile / 10.0
actual_rate = sum(outcomes) / len(outcomes)
if abs(expected_rate - actual_rate) > 0.15:
miscalibrated.append({
"decile": decile,
"expected": expected_rate,
"actual": actual_rate,
"sample_size": len(outcomes)
})
return CalibrationReport(
team=team,
miscalibrated_bins=miscalibrated,
needs_recalibration=len(miscalibrated) > 2
)Step 6: Review Planning for Large PRs
Small PRs (under 100 changed lines) get reviewed entirely. Every hunk goes through routing and sub-agent analysis. For large PRs (500+ changed lines across 15+ files), reviewing everything is wasteful. Some files are boilerplate, generated code, or test fixtures that don’t need LLM analysis.
The Planning Phase
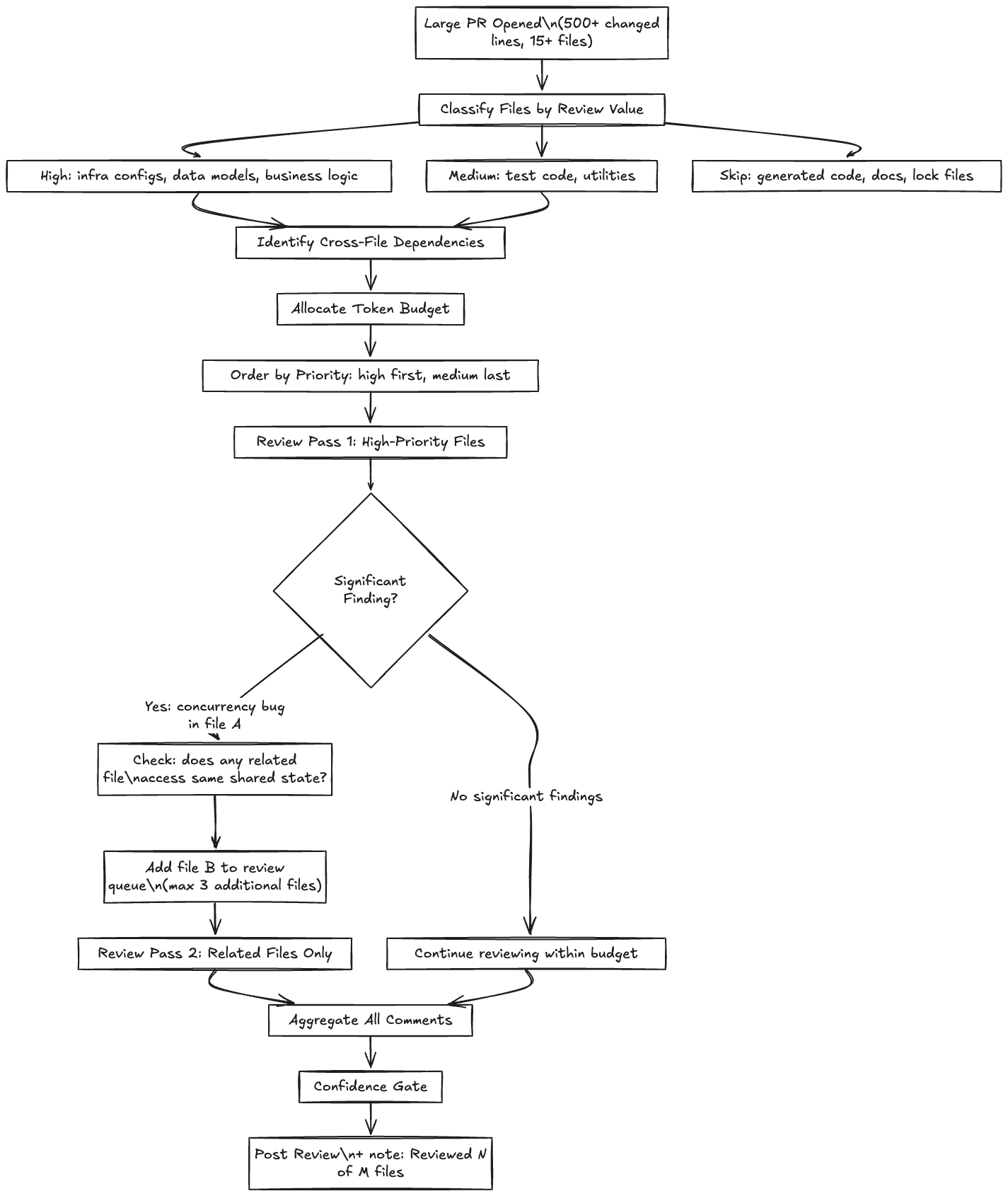
The PR Planner runs before any sub-agent is invoked. It:
- Classifies files by review value: infrastructure configs (high), business logic (high), data models (high), test code (medium), generated code (skip), documentation (skip)
- Identifies cross-file dependencies: if file A and file B both modify the same data model, review them together
- Estimates review budget: based on PR size, allocate a token budget. Large PRs get more budget but not linearly (a 1,000-line PR doesn’t get 10x the budget of a 100-line PR, more like 3-4x)
- Orders the review: critical files first, least-critical files last. If budget runs out, the remaining files are skipped with a note: “Large PR, reviewed N of M files. Focused on [list of reviewed files].”
class PRPlanner:
def plan_review(self, pr: PullRequest) -> ReviewPlan:
files = pr.get_changed_files()
classified = [
(f, self.classify_review_value(f))
for f in files
]
# Sort by review value (descending)
classified.sort(key=lambda x: x[1].priority, reverse=True)
budget = self.calculate_budget(pr.total_changed_lines)
planned_files = []
spent = 0
for file, classification in classified:
if classification.value == "skip":
continue
estimated_cost = self.estimate_review_cost(file)
if spent + estimated_cost > budget:
break
planned_files.append(file)
spent += estimated_cost
# Check for cross-file dependencies
dependency_groups = self.find_dependency_groups(planned_files)
return ReviewPlan(
files=planned_files,
skipped=[f for f, c in classified if f not in planned_files],
dependency_groups=dependency_groups,
budget_used=spent,
budget_total=budget
)Iterative Refinement
After the initial review pass, if a sub-agent finds a significant issue in file A (say, a concurrency bug), the planner can add related files to the review queue. “Found a race condition in file A around the user cache. File B also accesses the user cache. Adding file B to the review even though it was below the initial budget threshold.”
This iterative refinement is bounded: maximum one additional review pass, adding at most 3 files. Without the bound, the agent could spiral into reviewing the entire codebase by following dependency chains.
Failure Modes
1. Feedback Loop Collapse
The agent posts a comment with correct substance but poor phrasing. The reviewer dismisses it because the comment is confusing, not because the issue is wrong. The agent interprets the dismissal as “this isn’t an issue” and suppresses similar comments in the future. Over time, an entire class of valid findings is suppressed because of phrasing quality, not issue validity.
This is the most insidious failure mode because it’s self-reinforcing. The agent gets worse, which generates more dismissals, which makes it even worse.
Mitigation: track dismiss reasons separately. “Not an issue” reduces pattern confidence. “Poorly phrased” triggers prompt improvement without reducing pattern confidence. “Already addressed” is not negative feedback at all. The feedback UI needs to capture the reason, not just accept/dismiss.
2. Memory Poisoning from One Reviewer
Covered in Step 3, but the concrete failure scenario: a tech lead joins a new team and aggressively dismisses all agent comments for their first month (they prefer to do all reviews themselves). The agent learns to suppress most comments for that team. Six months later, the tech lead leaves, and the team has lost the agent’s coverage without realizing it.
The reviewer diversity weighting (requiring 3+ unique reviewers for full confidence updates) is the primary defense. But it’s worth monitoring for: if a team’s routing weights are significantly different from the organization average, flag for human review of the feedback distribution.
3. Stale Semantic Memory
Team conventions change. The payments team switched from optimistic to pessimistic locking after a new tech lead joined and redesigned the concurrency model. But the semantic memory still says “payments team uses optimistic locking.” The agent posts comments flagging pessimistic locking as a convention violation.
The decay factor (0.95 per week) is the primary defense. If no new signals reinforce “optimistic locking,” that memory’s confidence drops below the posting threshold in roughly 15-20 weeks. But that’s a long time to be posting wrong comments.
Faster mitigation: when a team member explicitly dismisses a convention-violation comment with “Not an issue, we changed this pattern,” the consolidation pipeline should immediately schedule a review of that semantic memory entry rather than waiting for the weekly cycle.
4. Planning Over-Investment on Trivial PRs
A 50-line PR that changes a README and adds a single test file. The planner classifies files, checks dependencies, estimates budget. Total planning overhead: 2 seconds of compute and 500 tokens. The review itself would have been faster without planning.
Prevention: skip the planning phase entirely for PRs under 100 changed lines and under 5 changed files. Just review everything. Planning only adds value when the review budget is genuinely constrained.
Operational Concerns
Monitoring
| Metric | What it tells you | Alert threshold |
|---|---|---|
| Comment acceptance rate (7-day rolling) | Overall agent quality | Below 60% (organization-wide) or below 50% (any team) |
| Mean time to first comment | Review latency | Above 10 minutes |
| Comments per PR distribution | Noise level | P90 above 5 comments per PR means gate is too permissive |
| Routing weight divergence | Team-specific adaptation quality | Any team+agent weight below 0.25 (approaching suppression) |
| Memory consolidation errors | Memory pipeline health | Any failure in weekly consolidation |
| Calibration drift (by team) | Confidence model accuracy | Any team with 3+ miscalibrated deciles |
| Feedback signal rate | Reviewer engagement with agent | Below 50% of comments receiving feedback (reviewers stopped bothering to accept/dismiss) |
The feedback signal rate is a meta-metric: if reviewers stop providing feedback, the learning loop breaks. The agent can’t adapt if no one tells it whether its comments are good or bad. A drop in feedback rate usually means the agent’s comments are so consistently wrong (or so consistently right) that reviewers don’t feel the need to respond. Either way, it needs investigation.
Cost Tracking
| Component | Cost per PR | Notes |
|---|---|---|
| Hunk analysis (sub-agents) | $0.08-0.25 | Varies with PR size and number of routed hunks |
| Planning (large PRs only) | $0.02-0.05 | Only for PRs with 200+ changed lines |
| Memory retrieval | Negligible | Vector search over semantic memory |
| Feedback processing | Negligible | Simple DB writes |
| Memory consolidation (weekly) | $5-15 per team | LLM-assisted pattern clustering |
| Total per PR | $0.10-0.30 | $200-1,200 per week at 2,000-4,000 PRs |
Gradual Rollout Strategy
-
Week 1-4: Shadow mode. Agent reviews every PR but only logs comments internally, doesn’t post them. Measure what acceptance rate would have been if comments were posted (by comparing agent findings with actual human review comments on the same PRs).
-
Week 5-8: Read-only mode on 5 volunteer teams. Agent posts comments but clearly labeled as “[AI Review - Beta]”. Collect feedback aggressively. Tune confidence thresholds per team.
-
Week 9-12: Expand to all teams with conservative thresholds (posting threshold 0.6 instead of 0.5). Adaptive routing begins learning from feedback.
-
Week 13+: Lower posting threshold to 0.5 as calibration stabilizes. Enable iterative review refinement for large PRs. Begin weekly memory consolidation.
The shadow mode phase is non-negotiable. It catches embarrassing failure modes (agent flags something as a bug that’s actually correct) before any developer sees them. A bad first impression during rollout is very hard to recover from.
Going Deeper
Fine-tuning vs retrieval for team conventions: The plan uses retrieval (semantic memory looked up at review time). An alternative is fine-tuning a small model per team on accepted/dismissed reviews. The fine-tuned model would internalize team conventions in its weights rather than retrieving them. The trade-off: fine-tuning captures behavioral nuance better (tone, severity calibration) but requires retraining whenever conventions change. With 50+ teams, maintaining 50 fine-tuned models is operationally expensive. Retrieval is more maintainable but slightly less natural. For most organizations, retrieval wins on operational simplicity. For a few high-volume teams (the top 5 by PR volume), a per-team fine-tune might justify its maintenance cost.
Cross-team convention sharing: Some conventions are universal (“don’t use SELECT * in production queries”). Others are team-specific. The memory consolidation pipeline can detect patterns that appear across many teams (accepted in 40+ teams) and promote them to organization-level semantic memory. This creates a natural knowledge-sharing mechanism: team A discovers a pattern, it gets accepted consistently, it propagates to the organization memory, and team B benefits without anyone writing documentation.
Integration with CI/CD agent: If the organization also runs the CI/CD pipeline agent, the two systems can exchange signals. The code review agent flagged a potential concurrency issue. The CI agent later sees a test failure consistent with a race condition. The CI agent’s diagnosis can reference the review agent’s earlier finding, strengthening both diagnoses. In the other direction, if the CI agent frequently diagnoses dependency conflicts in a particular service, the code review agent can increase its routing weight for dependency-related reviews in that service’s PRs.
Handling generated code and AI-authored PRs: As more code is AI-generated (Copilot, Claude Code, Cursor), the review agent sees PRs where much of the code was written by another LLM. This creates an interesting dynamic: the review agent might flag patterns that the code generation agent was instructed to produce. The solution is not to skip AI-authored code (it still needs review) but to adjust the review lens. AI-generated code has different failure modes than human-written code: it tends to be syntactically correct but architecturally naive, uses patterns from training data that may not match the codebase’s conventions, and sometimes generates plausible-looking code that doesn’t actually work. The sub-agents’ semantic memory should include patterns specific to AI-generated code issues.
References
[1] Anthropic — Building Effective Agents
[2] Google — Modern Code Review: A Case Study at Google
[3] Microsoft — CodeReview ML: Using ML to Improve Code Review
[4] Shopify Engineering — Building Production-Ready Agentic Systems
[6] Qdrant — Vector Database for Semantic Memory
[7] Google — Large-Scale Code Review at Google
[8] Meta — Sapienz: Intelligent Automated Software Testing
Note: This blog represents my technical views and production experience. I use AI-based tools to help with drafting and formatting to keep these posts coming daily.
← Back to all posts